RoboCup Junior Japan Rescue Kanto OB
2005~2013
2005~2013
×
[PR]上記の広告は3ヶ月以上新規記事投稿のないブログに表示されています。新しい記事を書く事で広告が消えます。
RadiumProduction へようこそ!
こちらは2007年より様々なジャンルで活動しているサークルRadiumProductionのブログです。
※2024年に個人同人活動の名義を全てRadiumProductionに統一しました。
世界中の人々の中の2人か3人くらいに有益な記事を書くことを目標に記事投稿を行っているブログです。
このブログ自体は元々RoboCup Juniorというロボット競技会に参加していた時に作られたものなので、
古い記事はロボット関係の記事が多かったですが、引退してここ10年くらいはIT系の記事が多いですね。
最近の記事の傾向としては「世界中どこにも載っていない記事」を書くことが多いです。
独自性で売っていくことにしました。今ドキの考え方ならNoteかQiitaに書いて金取るべきなんだろうな…
RCJ関係の方にとっては、Radium名義でRCJに出たこともありましたので色々ヤヤコシイですが、
Radiumという名称はRCJで使う前から元々コミックマーケットで使っていた自分の名義なので、
このブログは名実ともに、弊サークルのHPというのが正しい認識です。(後付け設定)
…実際C93以降のコミケ参加についてはこのブログでも一応のアナウンスをしていますし、
コミケットやISBN側に提出する書類にも、昔から常にこのブログを著者サイトとして申請しているので、まぁ嘘ではないです。
最後にこのブログを見るうえで一番大切なことを教えましょうか。
割と長いブログなので、記事も多いです。
記事も多いということは古い記事も多いです。
当然ですが、古い記事は古いので、今となっては役に立たない情報も多いです。
どうぞお気を付けください・・・。
それではどうか良い旅を。ブログって概念自体がもう骨董過ぎて負の遺産では・・・?
(^・ω・)ノ RadiumProduction at curonet
こちらは2007年より様々なジャンルで活動しているサークルRadiumProductionのブログです。
※2024年に個人同人活動の名義を全てRadiumProductionに統一しました。
世界中の人々の中の2人か3人くらいに有益な記事を書くことを目標に記事投稿を行っているブログです。
このブログ自体は元々RoboCup Juniorというロボット競技会に参加していた時に作られたものなので、
古い記事はロボット関係の記事が多かったですが、引退してここ10年くらいはIT系の記事が多いですね。
最近の記事の傾向としては「世界中どこにも載っていない記事」を書くことが多いです。
独自性で売っていくことにしました。今ドキの考え方ならNoteかQiitaに書いて金取るべきなんだろうな…
RCJ関係の方にとっては、Radium名義でRCJに出たこともありましたので色々ヤヤコシイですが、
Radiumという名称はRCJで使う前から元々コミックマーケットで使っていた自分の名義なので、
このブログは名実ともに、弊サークルのHPというのが正しい認識です。(後付け設定)
…実際C93以降のコミケ参加についてはこのブログでも一応のアナウンスをしていますし、
コミケットやISBN側に提出する書類にも、昔から常にこのブログを著者サイトとして申請しているので、まぁ嘘ではないです。
最後にこのブログを見るうえで一番大切なことを教えましょうか。
割と長いブログなので、記事も多いです。
記事も多いということは古い記事も多いです。
当然ですが、古い記事は古いので、今となっては役に立たない情報も多いです。
どうぞお気を付けください・・・。
それではどうか良い旅を。ブログって概念自体がもう骨董過ぎて負の遺産では・・・?
(^・ω・)ノ RadiumProduction at curonet
ブログ移転から今年で15年です(嘘だろ)本年もよろしくお願いいたします。
C107では既刊をバラまきました。C108は新刊をバラまきます。
実は最近高専の知り合いと飲む機会が多くなっておりまして、
何とこの1ヶ月で3回も。ぶっちゃけますとここ10年の高専会の半分以上がこの1ヶ月に集中しております。
別に今年が卒業何年の節目とか、そういう感じは特にないんですけどね。不思議です。
その中の1回は「TruthAcademyの閉校式のお疲れ様会かつ親睦会」というものに参加しておりました。
本体の閉校式は不参加なんですよね。なんで私ここに呼ばれたんだろう。
懐かしい方々と懐かしい話をすることができて大変有意義な時間となりました。
因みに、閉校式不参加の理由は・・・山でした。

閉校式の日程決定よりかなり前にこちらが決まっていたので、残念ながら・・・という事なのですが、
そして見てきたのはこの雲海。驚かれるかもしれませんが、なんとココは東京都です。
ちょうど東京と神奈川の県境でして、立ってる場所は東京なのですが、
目の前の看板には「神奈川県」と書いてあるかと思います。

角度を変えてみるとこのように、山の向こうからどんどん雲が溢れてきてるのが確認できます。
まさかこんなものを東京で見れるとは思っていなかったので非常に満足した登山でした。

因みに雲海の中はこんな感じ、意外と視界が開けており、楽しくトレッキングすることができました。
というのが近況(近況か?)報告となります。
登山ブログになってるんじゃないか?という説もありますが、それはきっと気のせいです。
では本年もよろしくお願いいたします。
(^・ω・)ノ RadiumProduction at curonet
C107では既刊をバラまきました。C108は新刊をバラまきます。
実は最近高専の知り合いと飲む機会が多くなっておりまして、
何とこの1ヶ月で3回も。ぶっちゃけますとここ10年の高専会の半分以上がこの1ヶ月に集中しております。
別に今年が卒業何年の節目とか、そういう感じは特にないんですけどね。不思議です。
その中の1回は「TruthAcademyの閉校式のお疲れ様会かつ親睦会」というものに参加しておりました。
本体の閉校式は不参加なんですよね。なんで私ここに呼ばれたんだろう。
懐かしい方々と懐かしい話をすることができて大変有意義な時間となりました。
因みに、閉校式不参加の理由は・・・山でした。
閉校式の日程決定よりかなり前にこちらが決まっていたので、残念ながら・・・という事なのですが、
そして見てきたのはこの雲海。驚かれるかもしれませんが、なんとココは東京都です。
ちょうど東京と神奈川の県境でして、立ってる場所は東京なのですが、
目の前の看板には「神奈川県」と書いてあるかと思います。
角度を変えてみるとこのように、山の向こうからどんどん雲が溢れてきてるのが確認できます。
まさかこんなものを東京で見れるとは思っていなかったので非常に満足した登山でした。
因みに雲海の中はこんな感じ、意外と視界が開けており、楽しくトレッキングすることができました。
というのが近況(近況か?)報告となります。
登山ブログになってるんじゃないか?という説もありますが、それはきっと気のせいです。
では本年もよろしくお願いいたします。
(^・ω・)ノ RadiumProduction at curonet
色々あってご挨拶が遅れましたが、C106ありがとうございました。
とりあえず前回の反省を活かしてサインを用意して臨んだC106でした。
サイン本は1冊だけこの世に産まれました。マジか・・・
今回も良い点悪い点で反省していきましょう。
よきかな
・誕生席
アドしかない。平和。しかも今回は向かいに島がない特殊な配置だったので楽 of 楽でした。
もう島中には戻れない・・・。
・通販予約をやったよ
前回0時打ちさせてしまった反省から、今回は事前予約を実施しました。
予約分は当日までに予約満了するほど盛況でして、やって良かったと思う次第であります。
・初合同誌なのに事故らなかった!
ぶっちゃけとにかくこれだけで本来100億点満点です。
合同誌なんて色々トラブルがつきもののハズですが、今回は目立ったトラブルなく入稿ができました。
これもひとえに参加頂きました皆様のご尽力あってのことです。
ダメかも
・印刷数足りんかったかも・・・
本当に、日和ったつもりは全くなかったんです。前回の印刷数を踏まえた上で、
それでもクソほど余る前提で刷ったのですが、何故か足りなくなりました。
コミケ当日に新刊一種完売を出し、現在通販分は新刊既刊とも完売、
手元在庫も新刊は一種完売、もう一種も残りわずかと、大変申し訳ないことになりました。
取材費等々考慮すると普通に完売でも赤字ですが・・・
今回は予約直後のタイミングで予約数を見て増刷をしたのですが、それでもなくなってしまいましたね。
「石油王が来ない限りなくならない数」だの「2,3年は戦える数」だの言いましたが、お詫びして訂正します。
実は石油王が来ていたのかもしれない・・・。
・エゴサができない
ちくしょう!またやりやがった!お前はいつもそうだ。
合同誌の方はエゴサ効くタイトルなのですが、もう一冊の方が完璧にダメでした。
学ぼう、はい。
最後に近況報告です。今年は富士山には行きませんでしたが、蔵王に行ってきました。

1年ぶり2回目の森林限界となります。
標高は1700m程度しかありませんが、緯度が上がると森林限界が下がるんだそうです。
C107に関してはサークルとしては不参加となります。
また次の夏、C108でお逢いしましょう。本格的に20周年が見えてきたな・・・?
(^・ω・)ノ RadiumProduction at curonet
とりあえず前回の反省を活かしてサインを用意して臨んだC106でした。
サイン本は1冊だけこの世に産まれました。マジか・・・
今回も良い点悪い点で反省していきましょう。
よきかな
・誕生席
アドしかない。平和。しかも今回は向かいに島がない特殊な配置だったので楽 of 楽でした。
もう島中には戻れない・・・。
・通販予約をやったよ
前回0時打ちさせてしまった反省から、今回は事前予約を実施しました。
予約分は当日までに予約満了するほど盛況でして、やって良かったと思う次第であります。
・初合同誌なのに事故らなかった!
ぶっちゃけとにかくこれだけで本来100億点満点です。
合同誌なんて色々トラブルがつきもののハズですが、今回は目立ったトラブルなく入稿ができました。
これもひとえに参加頂きました皆様のご尽力あってのことです。
ダメかも
・印刷数足りんかったかも・・・
本当に、日和ったつもりは全くなかったんです。前回の印刷数を踏まえた上で、
それでもクソほど余る前提で刷ったのですが、何故か足りなくなりました。
コミケ当日に新刊一種完売を出し、現在通販分は新刊既刊とも完売、
手元在庫も新刊は一種完売、もう一種も残りわずかと、大変申し訳ないことになりました。
取材費等々考慮すると普通に完売でも赤字ですが・・・
今回は予約直後のタイミングで予約数を見て増刷をしたのですが、それでもなくなってしまいましたね。
「石油王が来ない限りなくならない数」だの「2,3年は戦える数」だの言いましたが、お詫びして訂正します。
実は石油王が来ていたのかもしれない・・・。
・エゴサができない
ちくしょう!またやりやがった!お前はいつもそうだ。
合同誌の方はエゴサ効くタイトルなのですが、もう一冊の方が完璧にダメでした。
学ぼう、はい。
最後に近況報告です。今年は富士山には行きませんでしたが、蔵王に行ってきました。
1年ぶり2回目の森林限界となります。
標高は1700m程度しかありませんが、緯度が上がると森林限界が下がるんだそうです。
C107に関してはサークルとしては不参加となります。
また次の夏、C108でお逢いしましょう。本格的に20周年が見えてきたな・・・?
(^・ω・)ノ RadiumProduction at curonet
年1回。正月3が日だけ定期更新をしているブログはこちらになります。
旧年中は大変お世話になりました。2025年もよろしくお願い致します。
特にC105来て頂いた方は大変お世話になりました。
今回は1日目と2日目、両日サークルでしたのでたくさんの方にお会いすることができました。
去年は軽いノリで静岡行ったり山形行ったり長野行ったり富士山行ったりフランス行ったりと
とにかく多動な1年でした。とかいいつつ明日から新年会で泊まりで勝浦に行ってきます。
今日のテーマはタイトルの通りコミケの反省会です。
今回の話だけ聞きたい方はこちらをクリック
実は私は結構コミケ歴は長く、河童時代から裏でコミケサークルをやっていたりしているので
なんと今期で18年目になります。(実はRadiumという名前の初出はRCJではなくコミケなのです)
らじぷろ名義で初めて単独参加し、こちらのブログで告知したのが7年前のC93なのですが、
コミケ初参戦は2006年夏のC70となります、この時はサークルの手伝いとして参加し、
その後、C72を実質的な頒布物有の初参加として、次のC74と2年連続でサークル参加しております。
(冬コミはRCJと被るので不参加が基本でした。)
ただそのあと、高専に入学し、高専の試験期間とコミケが重なったことから
その後4年間、コミケへの参加はせず、次のサークル参加が2013年のC84となっています。(高専5年次)
その次は翌年のC86なのですが、そこから暫く企業ブースに入り浸りになるので
C86を最後に再び参加が途絶えます。
次の参加がまた間空きまして、C93、らじぷろ名義での初参加です。
その次はC98参加予定だったのですが、コロナで中止となりまして、その次がC100です。
C100は別名義で委託で無配を出して、C101もその余りを頒布しましたね。
C102、C103は何もなく、C104が前回、らじぷろ名義で無配の委託があり、そして次が今回です。
歴史は長いですが、実は本を出したことは3回しかありませんで、そのうち1冊はC93のコピー本です。
そんな数少ない本の頒布を行ったのが今回、C105となります。
-まとめ-
前置きが長くなりましたが、今回の感想を紹介していきましょう。
Good Point
・誕生日席最高!
サークルの特定を防ぐため詳細は省かせてもらいますが、
以前壁配置のサークルにお世話になったことがあるんです。
壁は広くて楽なのですが、その分来られる方も多いので諸々大変です。
島中は今度は狭すぎる。ウチは変な頒布が多い上に意外と人が来るので1スペースでは厳しさがある。
らじぷろの規模では壁は無理だけど島中は狭い。じゃあお誕生席は?と言いますと、これがもう最高でした。
今回初めての誕生席だったのですが、これはいいわ。次も狙っていきましょう(狙ってとれるものではありません)
・搬入数が神でした。
個人的な考え方として、割と完売させたくないという考え方があります。
特に最近は午後から入ってくる方も多く、なるべくなら赤字を出さない程度に在庫を残した状態で、
欲しい方に全て行き渡る形で幕を閉めたい、というのがあるのですが、
今回は2日間の頒布で、手持ちの残部数が1冊ずつ残るという、実質的なピタリ賞を取ることができました。
フランス旅行中にその場のノリで部数増やそう!と決めたのが功を奏しました。増やしてなかったら今頃・・・
・展示が良かったね。
サークルに置いた展示物がプチバズしまして、足を運んでくださった方が増えました。
その場のノリで考案した展示物でしたが、実現まで持っていけて本当に良かったです。
・事前の宣伝を頼んで良かった。
今回は知り合いに頼んでダイレクトマーケティングをして頂いました。
助かりました。
Bad Point...
・チケットが事故った
ごめんなさいでした。
・電子特典の資料を忘れた
SNSではしっかり紹介したのですが、現地で説明するパネル等が必要なのを失念していました。
実際に質問が何件かあったのです・・・
・外国語対応
外国人の購入者の方がいました。英語ならともかく中国語が無理でした。
Google翻訳を使えればよかったのですが、回線がクソでした。
どうすればよかったのだろうか・・・
・通販を0時打ちさせるな
メロブが落ちるのを失念していました。どうして。
・エゴサができない
本の名称が難解過ぎて誰も名前を呟かないのでエゴサが機能しません。
サークル名も略称である「らじぷろ」がコミケでは正式名称登録されているので
それも相まってエゴサが機能しません。本の感想が見れないじゃん。
・ネタをネタだと理解できない人にコミケは難しい
ネタをネタだと理解できない人対策を怠りました。まぁ燃えてはいないようですが・・・。
誤解は与えたかもしれないので、もうちょっとわかりやすくするべきだったね。
弊サークルでは石の販売はしておりません。
・サインを求められた
いや私絵描きじゃないんですが!!!!?????
作らなきゃダメ??????
とまぁこのような感じでしょうか。次回までにはある程度改善できればと思います。
え?サイン作るの・・・?
ところでなんで今まで、隠してきた別名義での過去の参加をここで公開したかと言いますと、
ちょっと最近忙しくなってきて、複数の名義での活動やサークルの維持が難しくなってきたんです。
ということで、今度の個人活動は、全てRadiumProducion傘下に一本化することになりました。
なので、これまでこちらからたどれるアカウントにて一切触れてこなかったようなジャンルの内容の本が
何の前触れもなく唐突にコミケで出てくる可能性があります。
ということでこれまでの活動歴を一本化したうえで、
歴史改変をして全てRadiumProducion関係だったということにしてしまいたいと思います(おい)
C106もここでは一切触れてないジャンルで新刊が出る予定となっております。
急な路線変更のように思うかもしれませんが、2025年もRadiumProducionをよろしくお願いいたします。
(^・ω・)ノ RadiumProduction at curonet
旧年中は大変お世話になりました。2025年もよろしくお願い致します。
特にC105来て頂いた方は大変お世話になりました。
今回は1日目と2日目、両日サークルでしたのでたくさんの方にお会いすることができました。
去年は軽いノリで静岡行ったり山形行ったり長野行ったり富士山行ったりフランス行ったりと
とにかく多動な1年でした。とかいいつつ明日から新年会で泊まりで勝浦に行ってきます。
今日のテーマはタイトルの通りコミケの反省会です。
今回の話だけ聞きたい方はこちらをクリック
実は私は結構コミケ歴は長く、河童時代から裏でコミケサークルをやっていたりしているので
なんと今期で18年目になります。(実はRadiumという名前の初出はRCJではなくコミケなのです)
らじぷろ名義で初めて単独参加し、こちらのブログで告知したのが7年前のC93なのですが、
コミケ初参戦は2006年夏のC70となります、この時はサークルの手伝いとして参加し、
その後、C72を実質的な頒布物有の初参加として、次のC74と2年連続でサークル参加しております。
(冬コミはRCJと被るので不参加が基本でした。)
ただそのあと、高専に入学し、高専の試験期間とコミケが重なったことから
その後4年間、コミケへの参加はせず、次のサークル参加が2013年のC84となっています。(高専5年次)
その次は翌年のC86なのですが、そこから暫く企業ブースに入り浸りになるので
C86を最後に再び参加が途絶えます。
次の参加がまた間空きまして、C93、らじぷろ名義での初参加です。
その次はC98参加予定だったのですが、コロナで中止となりまして、その次がC100です。
C100は別名義で委託で無配を出して、C101もその余りを頒布しましたね。
C102、C103は何もなく、C104が前回、らじぷろ名義で無配の委託があり、そして次が今回です。
歴史は長いですが、実は本を出したことは3回しかありませんで、そのうち1冊はC93のコピー本です。
そんな数少ない本の頒布を行ったのが今回、C105となります。
-まとめ-
C70 お手伝い。コミケ自体初参加
C72 初頒布。音楽系でした。
C74 2回目。こちらも音楽系です。
C84 始めて本を出しました。
C86 ソフトウェアを出しました。
C93 初めての個人参加。ソフトと本を出した。
C100 別名義で宣伝のための無配。
C101 別名義でC100の余りの頒布。
C104 宣伝のための無配。
C105 本2冊出し。
というわけで通算今回10回目、頒布アリとしては9回目のサークル参加となりました。前置きが長くなりましたが、今回の感想を紹介していきましょう。
Good Point
・誕生日席最高!
サークルの特定を防ぐため詳細は省かせてもらいますが、
以前壁配置のサークルにお世話になったことがあるんです。
壁は広くて楽なのですが、その分来られる方も多いので諸々大変です。
島中は今度は狭すぎる。ウチは変な頒布が多い上に意外と人が来るので1スペースでは厳しさがある。
らじぷろの規模では壁は無理だけど島中は狭い。じゃあお誕生席は?と言いますと、これがもう最高でした。
今回初めての誕生席だったのですが、これはいいわ。次も狙っていきましょう(狙ってとれるものではありません)
・搬入数が神でした。
個人的な考え方として、割と完売させたくないという考え方があります。
特に最近は午後から入ってくる方も多く、なるべくなら赤字を出さない程度に在庫を残した状態で、
欲しい方に全て行き渡る形で幕を閉めたい、というのがあるのですが、
今回は2日間の頒布で、手持ちの残部数が1冊ずつ残るという、実質的なピタリ賞を取ることができました。
フランス旅行中にその場のノリで部数増やそう!と決めたのが功を奏しました。増やしてなかったら今頃・・・
・展示が良かったね。
サークルに置いた展示物がプチバズしまして、足を運んでくださった方が増えました。
その場のノリで考案した展示物でしたが、実現まで持っていけて本当に良かったです。
・事前の宣伝を頼んで良かった。
今回は知り合いに頼んでダイレクトマーケティングをして頂いました。
助かりました。
Bad Point...
・チケットが事故った
ごめんなさいでした。
・電子特典の資料を忘れた
SNSではしっかり紹介したのですが、現地で説明するパネル等が必要なのを失念していました。
実際に質問が何件かあったのです・・・
・外国語対応
外国人の購入者の方がいました。英語ならともかく中国語が無理でした。
Google翻訳を使えればよかったのですが、回線がクソでした。
どうすればよかったのだろうか・・・
・通販を0時打ちさせるな
メロブが落ちるのを失念していました。どうして。
・エゴサができない
本の名称が難解過ぎて誰も名前を呟かないのでエゴサが機能しません。
サークル名も略称である「らじぷろ」がコミケでは正式名称登録されているので
それも相まってエゴサが機能しません。本の感想が見れないじゃん。
・ネタをネタだと理解できない人にコミケは難しい
ネタをネタだと理解できない人対策を怠りました。まぁ燃えてはいないようですが・・・。
誤解は与えたかもしれないので、もうちょっとわかりやすくするべきだったね。
弊サークルでは石の販売はしておりません。
・サインを求められた
いや私絵描きじゃないんですが!!!!?????
作らなきゃダメ??????
とまぁこのような感じでしょうか。次回までにはある程度改善できればと思います。
え?サイン作るの・・・?
ところでなんで今まで、隠してきた別名義での過去の参加をここで公開したかと言いますと、
ちょっと最近忙しくなってきて、複数の名義での活動やサークルの維持が難しくなってきたんです。
ということで、今度の個人活動は、全てRadiumProducion傘下に一本化することになりました。
なので、これまでこちらからたどれるアカウントにて一切触れてこなかったようなジャンルの内容の本が
何の前触れもなく唐突にコミケで出てくる可能性があります。
ということでこれまでの活動歴を一本化したうえで、
歴史改変をして全てRadiumProducion関係だったということにしてしまいたいと思います(おい)
C106もここでは一切触れてないジャンルで新刊が出る予定となっております。
急な路線変更のように思うかもしれませんが、2025年もRadiumProducionをよろしくお願いいたします。
(^・ω・)ノ RadiumProduction at curonet
2週間ほど前の話ですが、夏コミ対戦ありがとうございました。
今回は無料配布のみでしたが、冬コミはSP応募したので多分ちゃんと参加します。
実はコミティアに凱旋するという説もある・・・
ここ1年程はRaidiumProductionとしての活動は殆どMisskeyサーバーの運営になっているので、
こちらのブログはほとんど動いていませんね。

冬コミの新刊は恐らく技術本ではないのでこちらでは告知しない可能性が非常に高いですが、
ワンチャン別イベで出した技術本が出る可能性が微粒子レベルで存在します。
半分以上ただの生存報告ですか、今日はこの辺で。
(^・ω・)ノ RadiumProduction at curonet
今回は無料配布のみでしたが、冬コミはSP応募したので多分ちゃんと参加します。
実はコミティアに凱旋するという説もある・・・
ここ1年程はRaidiumProductionとしての活動は殆どMisskeyサーバーの運営になっているので、
こちらのブログはほとんど動いていませんね。
他に近況報告をするならば、先週、富士の頂にお散歩に行ったくらいでしょうか。
冬コミの新刊は恐らく技術本ではないのでこちらでは告知しない可能性が非常に高いですが、
ワンチャン別イベで出した技術本が出る可能性が微粒子レベルで存在します。
半分以上ただの生存報告ですか、今日はこの辺で。
(^・ω・)ノ RadiumProduction at curonet
昨日はロボカップジュニア関東ブロック20周年ということでイベントが開催されたということで。
お話は頂いていたのですが、ちょっとこちらがホストの別案件が重なっていて参加を見合わせていたのです。
ところが・・・
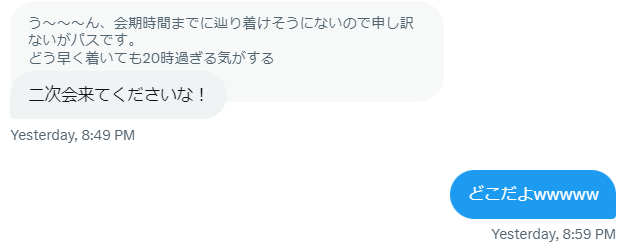
現ブロック長からこの世のものとは思えないほど雑なご招待を頂きまして、
二次会だけ途中参加させて頂きました。
本当に10年ぶりくらいに会う方が殆どでして、皆さんお変わりないようで非常に楽しい時間となりました。
産技高専自体にはコロナになる前まではちょくちょく行っていたのですが、
コロナ以降足が遠ざかっていたのでこういう機会を頂けて本当に良かったです。
取り急ぎ謝辞ということで。またこういう機会がちょくちょく発生するようですので
予定が合えばまた顔出せればと思います。昨日はありがとうございました。
(^・ω・)ノ RadiumProduction at curonet
お話は頂いていたのですが、ちょっとこちらがホストの別案件が重なっていて参加を見合わせていたのです。
ところが・・・
現ブロック長からこの世のものとは思えないほど雑なご招待を頂きまして、
二次会だけ途中参加させて頂きました。
本当に10年ぶりくらいに会う方が殆どでして、皆さんお変わりないようで非常に楽しい時間となりました。
産技高専自体にはコロナになる前まではちょくちょく行っていたのですが、
コロナ以降足が遠ざかっていたのでこういう機会を頂けて本当に良かったです。
取り急ぎ謝辞ということで。またこういう機会がちょくちょく発生するようですので
予定が合えばまた顔出せればと思います。昨日はありがとうございました。
(^・ω・)ノ RadiumProduction at curonet
2024年、新しい一年が始まりました。
本来ならお祝いムードのはずが一転、とんだ新年となってしまいました。
未だ全容が見えない災害ではありますが、 今回の震災で被害に遭われた方のご無事をお祈りしております。
本日の記事はMisskeyネタです。
時世がら投稿延期も考えたのですが、今日の話はこれもこれで必要情報かと思いましたので、予定通り書いていきます。
というのも、Misskeyバージョン2023.12.1の更新にて、このような変更がなされました。
・・・これ、とんでもないアホな話なんですよ。
順を追って説明していくと、最近のAPIはクラウドに習って最小特権の原則というものが採用されていて、
名称は色々あるけどまぁ全部中身は同じようなもん
APIキーなどの権限がかなり細分化されているんです。
これが令和のセキュリティのスタンダードになりつつありますね。
なので、細分化されてる中で、必要な権限だけが有効なAPIキーを作成するのが一般的なんですが、
途中で権限の内訳を変えるな。
これをやられると、キーを作り直さないといけなくなるんです。しかも何が厄介かというと・・・
どこがどう変わったのか説明がない。
つまり、キーが使えなくなった場合に何をどうしたら使えるようになるのかがわからないんです。
Misskeyは権限の種類が多く、ひとつひとつ試して確認するのも時間がかかるので、これの対処法は
全ての権限が有効になっているキーを作る。
になります。
本末転倒ですよね?まぁたまにMisskeyはこういう意味不明なアップデートがあります。
で、これで影響を受けたのがpipにあるMisskey.pyです。PythonからMisskeyAPIを使うライブラリですね。
これまで動いていたPythonで記述したMisskeyへのノート投稿プログラムが、
Misskeyをアップデートしたらこんなエラーが返ってくるように。
GASで書いた方は特に影響を受けていなかったのですが、
どうにもMisskey.pyは今回の仕様変更の影響を受けたようです。
・・・いや、ふざけんなよ。
という訳で、API KEYのサイレントナーフにより、
Pythonを利用したMisskey関連ツールのほぼ全システムがダウンするという、
まぁ割ととんでもなく質の悪いアップデートが年末の忙しい時期に実施された、というお話でした。
最低限何を有効にしたらMisskey.pyが利用できるのかはそのうち調べようとは思いますが、
いかんせん最近忙しいので、取り急ぎこの記事はこの辺でいったんお開きとさせて頂きます。
コミケ終わっておうち帰ってみたらPython製のぼっとが全部死んでて流石にビビったよ・・・
それではまた次回の記事で~
(^・ω・)ノ RadiumProduction at curonet
本来ならお祝いムードのはずが一転、とんだ新年となってしまいました。
未だ全容が見えない災害ではありますが、 今回の震災で被害に遭われた方のご無事をお祈りしております。
本日の記事はMisskeyネタです。
時世がら投稿延期も考えたのですが、今日の話はこれもこれで必要情報かと思いましたので、予定通り書いていきます。
というのも、Misskeyバージョン2023.12.1の更新にて、このような変更がなされました。
・アクセストークンの権限が再整理されたため、一部のAPIが古いAPIトークンでは動作しなくなりました。 権限不足になる場合には権限を再設定して再生成してください。Misskeyリリースノートより
・・・これ、とんでもないアホな話なんですよ。
順を追って説明していくと、最近のAPIはクラウドに習って最小特権の原則というものが採用されていて、
名称は色々あるけどまぁ全部中身は同じようなもん
APIキーなどの権限がかなり細分化されているんです。
これが令和のセキュリティのスタンダードになりつつありますね。
なので、細分化されてる中で、必要な権限だけが有効なAPIキーを作成するのが一般的なんですが、
途中で権限の内訳を変えるな。
これをやられると、キーを作り直さないといけなくなるんです。しかも何が厄介かというと・・・
どこがどう変わったのか説明がない。
つまり、キーが使えなくなった場合に何をどうしたら使えるようになるのかがわからないんです。
Misskeyは権限の種類が多く、ひとつひとつ試して確認するのも時間がかかるので、これの対処法は
全ての権限が有効になっているキーを作る。
になります。
本末転倒ですよね?まぁたまにMisskeyはこういう意味不明なアップデートがあります。
で、これで影響を受けたのがpipにあるMisskey.pyです。PythonからMisskeyAPIを使うライブラリですね。
これまで動いていたPythonで記述したMisskeyへのノート投稿プログラムが、
Misskeyをアップデートしたらこんなエラーが返ってくるように。
File "/home/misskirara/.local/lib/python3.10/site-packages/misskey/misskey.py", line 99, in token
raise MisskeyAuthorizeFailedException()
misskey.exceptions.MisskeyAuthorizeFailedException
Traceback (most recent call last):
GASで書いた方は特に影響を受けていなかったのですが、
どうにもMisskey.pyは今回の仕様変更の影響を受けたようです。
・・・いや、ふざけんなよ。
という訳で、API KEYのサイレントナーフにより、
Pythonを利用したMisskey関連ツールのほぼ全システムがダウンするという、
まぁ割ととんでもなく質の悪いアップデートが年末の忙しい時期に実施された、というお話でした。
最低限何を有効にしたらMisskey.pyが利用できるのかはそのうち調べようとは思いますが、
いかんせん最近忙しいので、取り急ぎこの記事はこの辺でいったんお開きとさせて頂きます。
コミケ終わっておうち帰ってみたらPython製のぼっとが全部死んでて流石にビビったよ・・・
それではまた次回の記事で~
(^・ω・)ノ RadiumProduction at curonet
前回に引き続いているのはちょっとわかりませんが、第6回の記事です。
今回はタイトルの通り、v2023.11.0にて実装されたプラグイン配布のやり方についてです。
Misskeyのインスタンスを建てた話。①(Misskey紹介編)
Misskeyのインスタンスを建てた話。②(GCPでの建ち上げ編)
Misskeyのインスタンスを建てた話。③(OCIでの建ち上げ編)
Misskeyのインスタンスを建てた話。④(Webhookで対話bot作成編)
Misskeyのインスタンスを建てた話。⑤(Meilisearch導入編)
Misskeyにはプラグインという機能があります。説明略。ここ読んでね。
これまでプラグインの導入には設定のプラグインに直接プラグインを記述する必要があり、
なんともギークな手法でしか使うことができない機能だったのですが、
v2023.11.0のアップデートにてAPIによる配布ができるようになりました。
ということで、今回の記事はこの配布方法について紹介します。
公式にもこのようなページがあるのですが、情報が派手に不足しているので補足も兼ねて、というところです。
まず、プラグインを作ります。
とりあえず既存の作成方法と同じようにプラグインを作って動くかどうか確認しましょう。
今回はこんな感じでノート全文にブラーのMFMを追加するプラグインを作成します。
変換間違いやスペースの誤削除に注意してください。
※公式にハッシュ化する範囲についての記載が一切なかったので詰まったのですが、範囲はソースのみです。jsonファイル全体ではありません。
以上がMisskeyのプラグインのAPI経由での配布についてでした。
因みにですが、URLのホストの部分はプラグイン利用者が任意に入れるようにするのが主流のようです。
これでMisskeyのプラグインの文化がより広がりそうですね。
Googleアカウントがあれば誰でも可能な方法ですので、是非お試しあれ。
(^・ω・)ノ RadiumProduction at curonet
今回はタイトルの通り、v2023.11.0にて実装されたプラグイン配布のやり方についてです。
Misskeyのインスタンスを建てた話。①(Misskey紹介編)
Misskeyのインスタンスを建てた話。②(GCPでの建ち上げ編)
Misskeyのインスタンスを建てた話。③(OCIでの建ち上げ編)
Misskeyのインスタンスを建てた話。④(Webhookで対話bot作成編)
Misskeyのインスタンスを建てた話。⑤(Meilisearch導入編)
Misskeyにはプラグインという機能があります。説明略。ここ読んでね。
これまでプラグインの導入には設定のプラグインに直接プラグインを記述する必要があり、
なんともギークな手法でしか使うことができない機能だったのですが、
v2023.11.0のアップデートにてAPIによる配布ができるようになりました。
ということで、今回の記事はこの配布方法について紹介します。
公式にもこのようなページがあるのですが、情報が派手に不足しているので補足も兼ねて、というところです。
まず、プラグインを作ります。
とりあえず既存の作成方法と同じようにプラグインを作って動くかどうか確認しましょう。
今回はこんな感じでノート全文にブラーのMFMを追加するプラグインを作成します。
/// @ 0.16.0
### {
name: "blur"
author: "curonet"
version: 1
description: "ノート全文にblurをかけます。"
}
Plugin:register_post_form_action("blur" @(form, update) {
let updated_text = ["$[blur ",form.text,"]"].join()
update("text", updated_text)
})
正常に動作することを確認したら、これを配布できるようにします。まず最初に改行コードをLFに変換して、ソース全文をSHA-512でハッシュ化します。
Windows使ってる場合はこれ面倒ですね。自分はsublime textの置換(regular exprassionオプション)でやってます。
ハッシュ化はこちらのサイトを使うことで簡単に行うことができますね。
終わったらそのハッシュ値をメモ帳にでもコピーしておいてください。後で使います。
次にAPIサーバを作成します。
まぁ色々作る方法はありますが、一番簡単なのはやはりGASだと思います。
GoogleDriveを開いて新規にGASを作成します。
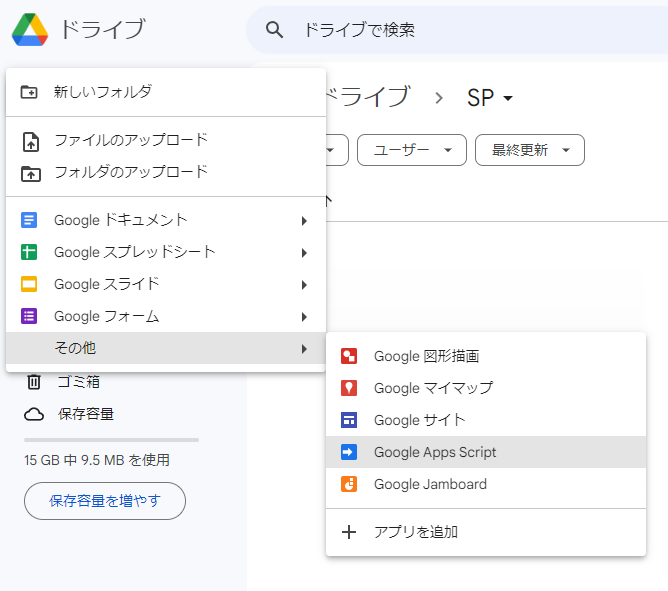
そして、開いたGASに下記を記入して保存します。
ソース中の ' や"は\でエスケープし、改行は\nに置換してください。
※置換の際はハッシュ化した際のソースと改行の数まで正確に完全一致させてください。
そしてこれをAPIとして新規にデプロイします。
デプロイ手順はGASの仕様がコロコロ変わるせいで、書いてもあまり意味がないので割愛しますが、
APIか、なければwebアプリケーションでのデプロイで動くと思います。
デプロイしたらURLが発行されると思うので、これをコピーします。
この際にブラウザにURLをコピーしてAPIを叩き、正常に結果が返ってきていることを確認しておきましょう。
そして下記リンクを穴埋めして完成です。
{API_URL} →GASから発行されたURL
{HASH} →生成したハッシュ値
これで、このリンクを踏むとプラグインのインストールページに遷移することができます。
また、下記のような画面になった場合はハッシュ化したソースとGASに書いたソースが異なっているので、
ハッシュの再生成を行うなどして対応してください。
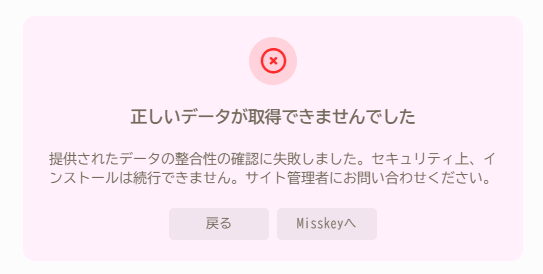
セキュリティ(プラグインの改竄防止)のためにハッシュによる比較を行っているので、
改行だろうがスペースだろうが、データ上1点でも違いがあれば弾かれるようになっています。
Windows使ってる場合はこれ面倒ですね。自分はsublime textの置換(regular exprassionオプション)でやってます。
ハッシュ化はこちらのサイトを使うことで簡単に行うことができますね。
終わったらそのハッシュ値をメモ帳にでもコピーしておいてください。後で使います。
次にAPIサーバを作成します。
まぁ色々作る方法はありますが、一番簡単なのはやはりGASだと思います。
GoogleDriveを開いて新規にGASを作成します。
そして、開いたGASに下記を記入して保存します。
function doGet(e) {
return ContentService.createTextOutput(JSON.stringify({'type': 'plugin','data': '<ソース>'))
.setMimeType(ContentService.MimeType.JSON);
}
<ソース>の箇所にはプラグインのソース全文を記載します。ソース中の ' や"は\でエスケープし、改行は\nに置換してください。
※置換の際はハッシュ化した際のソースと改行の数まで正確に完全一致させてください。
そしてこれをAPIとして新規にデプロイします。
デプロイ手順はGASの仕様がコロコロ変わるせいで、書いてもあまり意味がないので割愛しますが、
APIか、なければwebアプリケーションでのデプロイで動くと思います。
デプロイしたらURLが発行されると思うので、これをコピーします。
この際にブラウザにURLをコピーしてAPIを叩き、正常に結果が返ってきていることを確認しておきましょう。
そして下記リンクを穴埋めして完成です。
https://{HOST}/install-extentions?url={API_URL}&hash={HASH}
{HOST} →プラグインをインストールするMisskeyのホスト名{API_URL} →GASから発行されたURL
{HASH} →生成したハッシュ値
これで、このリンクを踏むとプラグインのインストールページに遷移することができます。
また、下記のような画面になった場合はハッシュ化したソースとGASに書いたソースが異なっているので、
ハッシュの再生成を行うなどして対応してください。
セキュリティ(プラグインの改竄防止)のためにハッシュによる比較を行っているので、
改行だろうがスペースだろうが、データ上1点でも違いがあれば弾かれるようになっています。
変換間違いやスペースの誤削除に注意してください。
※公式にハッシュ化する範囲についての記載が一切なかったので詰まったのですが、範囲はソースのみです。jsonファイル全体ではありません。
以上がMisskeyのプラグインのAPI経由での配布についてでした。
因みにですが、URLのホストの部分はプラグイン利用者が任意に入れるようにするのが主流のようです。
これでMisskeyのプラグインの文化がより広がりそうですね。
Googleアカウントがあれば誰でも可能な方法ですので、是非お試しあれ。
(^・ω・)ノ RadiumProduction at curonet
前回に引き続き、第5回の記事です。
今回はタイトルの通り、MisskeyにMeilisearchという検索エンジンを導入する話です。
Misskeyのインスタンスを建てた話。①(Misskey紹介編)
Misskeyのインスタンスを建てた話。②(GCPでの建ち上げ編)
Misskeyのインスタンスを建てた話。③(OCIでの建ち上げ編)
Misskeyのインスタンスを建てた話。④(Webhookで対話bot作成編)
Misskeyにはノート用の検索システムが標準で搭載されているのですが、
Misskeyの標準のノート検索は時間がかかる上に、サーバーに多大な負荷を与えてしまうことから、
デフォルトでロールによりノート検索は無効になっています。
なので、従来の中規模以上のインスタンスではノート検索の有効化は非常に覚悟のいる行為でした。
しかし13.12.0バージョンからMisskeyでは、
Meilisearchという外部の検索エンジンを利用することができるようになりました。
Meilisearchは逐次検索やタイプミス耐性、ファセット検索、ジオサーチ、マルチテナンシーなどが利用でき、
何より最近注目のRustで作成されており、動作が超高速ということでリリース早々にして有名になりました。
この手のやつは日本語があやふやなことが多いのですが、ちゃんと日本語の形態素解析(Lindera)に対応しています。
今回はMisskeyにMeilisearchを導入する手法について解説していこうと思います。
こちらのサイトを参考にしたのですが、この内容が投稿されたしばらく後、バージョン13.12.2において
仕様が変更されてしまっているので一部内容を書き換えたものを掲載します。
※MisskeyのMeilisearchはSQLからjsonファイルを書き出した後、その内容を受け取って全文探索をします。
そのため、ディスクIOを非常に多く行うので、オンプレミスでMisskeyを建てている場合はその点にご留意ください。
特にSSDを利用している場合は注意が必要ですね。モニタリングしてないとディスクがヤバスです。
まずはインストール。Meilisearchはサーバを建ててHTTPのリクエストを飛ばして利用する感じです。
つまり、Misskey本体サーバとサーバを分けて運用することが可能となっております。
ウチもそのうち分けようと思っていますが、リソースに余裕があるのでひとまず同一サーバで建ててみます。
下記のコマンドを順に実行します。
次に./meilisearch.tomlファイルを編集します。下記の項目を編集します。
master_keyは任意に設定する値です。MisskeyからAPI送信時のキーになるものです。
db_path、dump_dir、snapshot_dir をMeilisearchインストール時に作成されたフォルダ配下に設定します。
no_analyticsですが、Meilisearchはデフォルトでテレメトリデータを開発元に送信する機能があります。
テレメトリデータから個人や検索内容の特定等はできないようですが、
テレメトリデータが個人情報に当たるケース(カリフォルニア州消費者プライバシー法など)があるらしいので
各インスタンスの規約や、通信量的に好ましくない場合は、no_analyticsをtrueにすると、送信しなくなります。
次に、この編集データの反映作業です。tomlファイルの移動やディレクトリ作成ですね。
次に下記の /etc/systemd/system/meilisearch.service ファイルを作成してsystemlctlから利用できるようにします。
終わったら下記コマンドでMeilisearchを有効にします。
次に、Misskeyの過去のノートをMeilisearchから検索できるようにindexを貼ります。
この作業を行わないと、Meilisearch導入以前のノートが検索できなくなってしまいます。
DB名、LIMIT後の数値、INDEX名、MASTER_KEYの編集が必要です。
DB名はMisskeyのpostgresのDB名(デフォルトはmk1)に置換してください。
LIMITの数値は適当に200000にしていますが、現在の総ノート数を確認して記述する等にしてください。
INDEX名に利用するインデックスの名前を記述します。ここは一般に「インスタンスホスト名---note」になります。
バージョン13.12.2以降、MisskeyではMeilisearchの利用にindexが必要になりました。
後述するdefault.ymlで設定したindexの値に---noteがpostfixされた値がindexとなるので、
現在のmisskeyでは、ここでのinde貼りはこの形式に合わせる必要があります。
MASTER_KEYは先ほどご自身で設定されたmaster_keyになります。
最後にMisskey側でMeilisearchを使えるように、misskey/.config/default.yml の設定を行います。
MASTER_KEYとインスタンスホスト名は上のコマンドと同じです。
ここまで設定が完了したらsystemcltでMisskeyの再起動と、Meilisearchの起動を行います。
といっても、総ノート数が4桁~5桁前半ぐらいのインスタンスではあまり変化が見られないと思うので、
おひとり様インスタンスでは実感がないかもですね。個人的にはお一人様インスタンスでは不要だと思ってます。
再びになりますが、注意点として
・日本語も対応してるが、形態素解析結果によっては正しい検索結果を返さないことがある。
・Misskeyのノート検索はロールによってデフォルトで無効にされている。
今回はタイトルの通り、MisskeyにMeilisearchという検索エンジンを導入する話です。
Misskeyのインスタンスを建てた話。①(Misskey紹介編)
Misskeyのインスタンスを建てた話。②(GCPでの建ち上げ編)
Misskeyのインスタンスを建てた話。③(OCIでの建ち上げ編)
Misskeyのインスタンスを建てた話。④(Webhookで対話bot作成編)
Misskeyにはノート用の検索システムが標準で搭載されているのですが、
Misskeyの標準のノート検索は時間がかかる上に、サーバーに多大な負荷を与えてしまうことから、
デフォルトでロールによりノート検索は無効になっています。
なので、従来の中規模以上のインスタンスではノート検索の有効化は非常に覚悟のいる行為でした。
しかし13.12.0バージョンからMisskeyでは、
Meilisearchという外部の検索エンジンを利用することができるようになりました。
Meilisearchは逐次検索やタイプミス耐性、ファセット検索、ジオサーチ、マルチテナンシーなどが利用でき、
何より最近注目のRustで作成されており、動作が超高速ということでリリース早々にして有名になりました。
この手のやつは日本語があやふやなことが多いのですが、ちゃんと日本語の形態素解析(Lindera)に対応しています。
今回はMisskeyにMeilisearchを導入する手法について解説していこうと思います。
こちらのサイトを参考にしたのですが、この内容が投稿されたしばらく後、バージョン13.12.2において
仕様が変更されてしまっているので一部内容を書き換えたものを掲載します。
※MisskeyのMeilisearchはSQLからjsonファイルを書き出した後、その内容を受け取って全文探索をします。
そのため、ディスクIOを非常に多く行うので、オンプレミスでMisskeyを建てている場合はその点にご留意ください。
特にSSDを利用している場合は注意が必要ですね。モニタリングしてないとディスクがヤバスです。
まずはインストール。Meilisearchはサーバを建ててHTTPのリクエストを飛ばして利用する感じです。
つまり、Misskey本体サーバとサーバを分けて運用することが可能となっております。
ウチもそのうち分けようと思っていますが、リソースに余裕があるのでひとまず同一サーバで建ててみます。
下記のコマンドを順に実行します。
sudo apt install curl -y curl -L https://install.meilisearch.com | sh chmod +x meilisearch sudo mv ./meilisearch /usr/local/bin/ sudo useradd -d /var/lib/meilisearch -b /bin/false -m -r meilisearch curl https://raw.githubusercontent.com/meilisearch/meilisearch/latest/config.toml > ./meilisearch.tomlこれでインストールが完了します。
次に./meilisearch.tomlファイルを編集します。下記の項目を編集します。
env = "production" master_key ="16byte以上の任意の値" db_path = "/var/lib/meilisearch/data" dump_dir = "/var/lib/meilisearch/dumps" snapshot_dir = "/var/lib/meilisearch/snapshots" no_analytics = trueenvをproductionにします。
master_keyは任意に設定する値です。MisskeyからAPI送信時のキーになるものです。
db_path、dump_dir、snapshot_dir をMeilisearchインストール時に作成されたフォルダ配下に設定します。
no_analyticsですが、Meilisearchはデフォルトでテレメトリデータを開発元に送信する機能があります。
テレメトリデータから個人や検索内容の特定等はできないようですが、
テレメトリデータが個人情報に当たるケース(カリフォルニア州消費者プライバシー法など)があるらしいので
各インスタンスの規約や、通信量的に好ましくない場合は、no_analyticsをtrueにすると、送信しなくなります。
次に、この編集データの反映作業です。tomlファイルの移動やディレクトリ作成ですね。
sudo cp ./meilisearch.toml /etc/meilisearch.toml sudo mkdir /var/lib/meilisearch/data /var/lib/meilisearch/dumps /var/lib/meilisearch/snapshots sudo chown -R meilisearch:meilisearch /var/lib/meilisearch sudo chmod 750 /var/lib/meilisearch難しいことは特にしていないので流しで。
次に下記の /etc/systemd/system/meilisearch.service ファイルを作成してsystemlctlから利用できるようにします。
[Unit] Description=Meilisearch After=systemd-user-sessions.service [Service] Type=simple WorkingDirectory=/var/lib/meilisearch ExecStart=/usr/local/bin/meilisearch --config-file-path /etc/meilisearch.toml User=meilisearch Group=meilisearch [Install] WantedBy=multi-user.target
終わったら下記コマンドでMeilisearchを有効にします。
sudo systemctl daemon-reload sudo systemctl enable --now meilisearch
次に、Misskeyの過去のノートをMeilisearchから検索できるようにindexを貼ります。
この作業を行わないと、Meilisearch導入以前のノートが検索できなくなってしまいます。
cd /var/tmp/
sudo -u postgres psql -d DB名 -c "SELECT json_agg(row_to_json(t)) ::text FROM (SELECT id, \"createdAt\", \"userId\", \"userHost\", \"channelId\",cw,text FROM note WHERE visibility IN ('home', 'public')LIMIT 200000) t" > /var/tmp/notes_tmp
sed -i '1d;2d;x;$d;' notes_tmp
jq 'map(.createdAt |= (strptime("%Y-%m-%dT%H:%M:%S%Z") | mktime | . * 1000 + (. / 1000000 | floor)))' notes_tmp > notes.json
curl -X POST 'http://localhost:7700/indexes/INDEX名/documents?primaryKey=id' --data-binary @notes.json -H 'Content-Type: application/json' -H "Authorization: Bearer MASTER_KEY"
DB名、LIMIT後の数値、INDEX名、MASTER_KEYの編集が必要です。
DB名はMisskeyのpostgresのDB名(デフォルトはmk1)に置換してください。
LIMITの数値は適当に200000にしていますが、現在の総ノート数を確認して記述する等にしてください。
INDEX名に利用するインデックスの名前を記述します。ここは一般に「インスタンスホスト名---note」になります。
バージョン13.12.2以降、MisskeyではMeilisearchの利用にindexが必要になりました。
後述するdefault.ymlで設定したindexの値に---noteがpostfixされた値がindexとなるので、
現在のmisskeyでは、ここでのinde貼りはこの形式に合わせる必要があります。
MASTER_KEYは先ほどご自身で設定されたmaster_keyになります。
最後にMisskey側でMeilisearchを使えるように、misskey/.config/default.yml の設定を行います。
meilisearch: host: localhost port: 7700 apiKey: 'MASTER_KEY' index: 'インスタンスホスト名'サーバーを分けるときはhostを別のマシンのものに変更しましょう。
MASTER_KEYとインスタンスホスト名は上のコマンドと同じです。
ここまで設定が完了したらsystemcltでMisskeyの再起動と、Meilisearchの起動を行います。
sudo systemctl start meilisearch sudo systemctl restart misskirara.net多分これで検索にMeilisearchが使えるようになっていると思います。
といっても、総ノート数が4桁~5桁前半ぐらいのインスタンスではあまり変化が見られないと思うので、
おひとり様インスタンスでは実感がないかもですね。個人的にはお一人様インスタンスでは不要だと思ってます。
再びになりますが、注意点として
・日本語も対応してるが、形態素解析結果によっては正しい検索結果を返さないことがある。
・Misskeyのノート検索はロールによってデフォルトで無効にされている。
・オンプレの場合はディスクIOに気を付ける。
・indexが必須になるアップデートがあったので、旧来の方法では動かない。
13.12.2 以前からMeilisearchを利用している場合は、
こちらの手順を使ってindexを張り替えることで、古いノートも検索ができるようになります。
以上がMisskeyのノート検索でMeilisearchを利用する手順となります。
Misskeyは開発思想が先進的であるが故に、割と古い機能がすぐ廃止になったり変更になったりと、
モデレーションする側としてはなかなかに胃の痛いシステムです。
開発開始から10年以上建っているのに未だに安定しないのもちょっと困りものですね・・・
という訳で今回はここまでです。また何か書くべきことがあれば更新しようと思います~
(^・ω・)ノ RadiumProduction at curonet
・indexが必須になるアップデートがあったので、旧来の方法では動かない。
13.12.2 以前からMeilisearchを利用している場合は、
こちらの手順を使ってindexを張り替えることで、古いノートも検索ができるようになります。
以上がMisskeyのノート検索でMeilisearchを利用する手順となります。
Misskeyは開発思想が先進的であるが故に、割と古い機能がすぐ廃止になったり変更になったりと、
モデレーションする側としてはなかなかに胃の痛いシステムです。
開発開始から10年以上建っているのに未だに安定しないのもちょっと困りものですね・・・
という訳で今回はここまでです。また何か書くべきことがあれば更新しようと思います~
(^・ω・)ノ RadiumProduction at curonet
前回に引き続き、第4回の記事です。
今回はタイトルの通り、対話botを作る話です。
Misskeyのインスタンスを建てた話。①(Misskey紹介編)
Misskeyのインスタンスを建てた話。②(GCPでの建ち上げ編)
Misskeyのインスタンスを建てた話。③(OCIでの建ち上げ編)
普通はMisskeyの立ち上げと来たら設定とか、オブジェクトストレーシとか
そういう記事が次に来るべきだとは思うのですが、
そういうの、もうあるじゃん。
インターネットの海にアホほど転がっている情報を、今更ここで焼き鈍すことに価値があるのか?
と言うことで、ネットの海になさそうな情報を記事として書くことにしました。
Tips
・Misskeyの設定は基本的に管理画面からできます。
・~/misskey/.config/default.yml を編集することでサーバ側の設定ができます。
・特に個人サーバの場合はCloudflareによる保護を検討しましょう。
・オブジェクトストレージはウチはCloudflare R2を使ってます。おススメです。
以上終わり!多分この辺の単語でググればいろいろ出てきます!
まぁ暇だったらウチでちゃんと記事を書くかもしれませんが、余り暇じゃないので多分書かないです。
で、本題なのですが、Twitterではbotと言えば、Streamをでツイートを取得してから自分宛てのツイートを拾って、
それに対して返信をしていく・・・みたいな処理になったかと思うのですが、
何故か今回は違う方法を使っています。
MisskeyにもStream機能はあって実際に使ってみたりもしたのですが、受信はできた
MisskeyのストリーミングAPIはドキュメントが雑にしか書かれていなくて使い方が殆どわからなく、
ネットにも特に新しい情報がないのでよくわからなかったのと、
inputパラメータに何があるかくらいは書いて欲しいんですよね・・・
全てのノートをストリーミングする処理はぼっと用サーバにかかる負担が大きくなることから、
今回は別の手法としてMisskeyに実装されているWebhookを採用しました。
Webhookというのは簡単に言うとネットワークに対して発信できる通知機能のようなものですね。
今回はMisskeyのbotアカウントへのメンションをトリガにして、Webhookを飛ばします。
飛んでくるデータ形式はjsonですので、受け取りさえできれば扱いは簡単です。
それを受けて返信を書いてやろうという魂胆です。
ただ、Webhookは受信用のサーバを建てる必要があります。pythonのモジュールで簡単に建つは建つのですが、
今回はオンプレサーバは使いたくないし、これ以上OCIにもGCPにも負荷をかけたくなかったので
Makeというノーコードツールを導入することにしました。
これはノーコードでアプリケーションパイプラインを構築することができるツールで
月間1000回までなら無料で利用することができます。
まずアカウントを作ってたら左サイドバーのScenariosをクリックしてから右上のCreate a new scenarioを選択します。
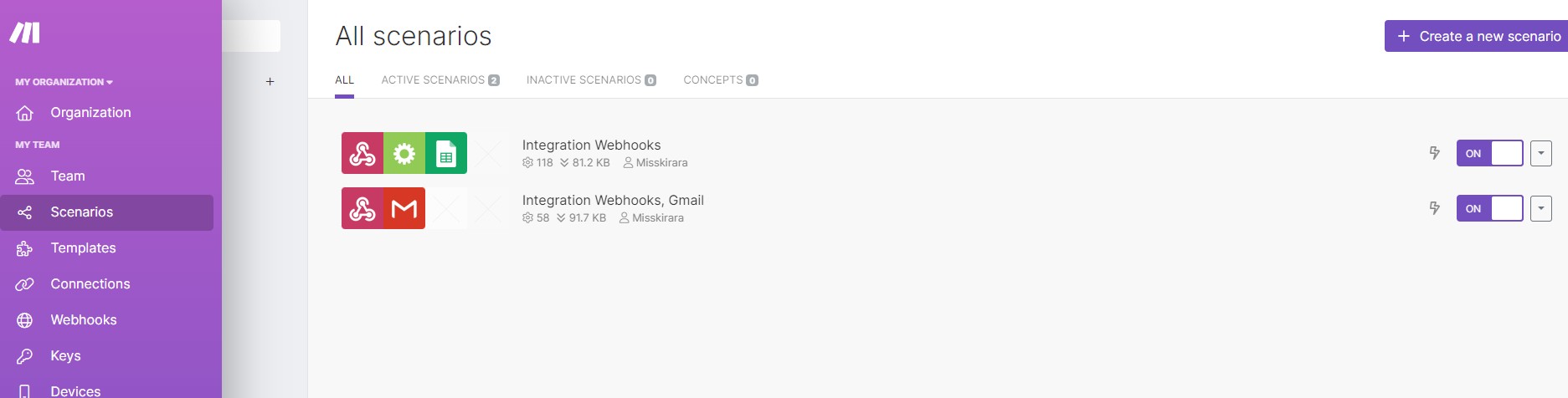
そしたらシナリオ画面に行くので真ん中の丸を押して新しいノードを作ります。
今回はWebhookの受信をするので、下の検索欄にwebと打ってWebhooksを選択します。
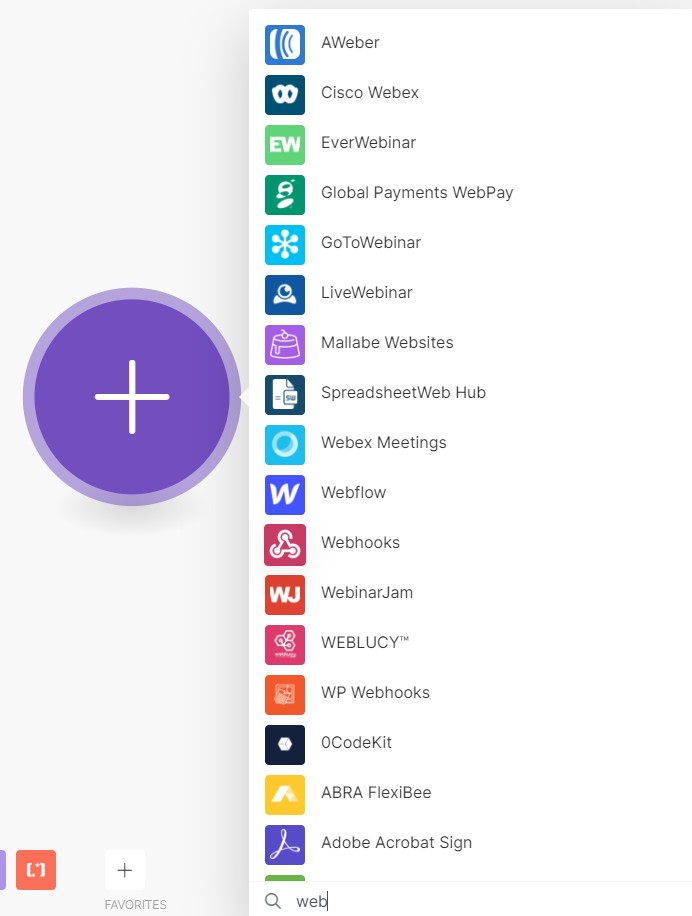
3つ出てくるのでCustom Webhookを選択します。
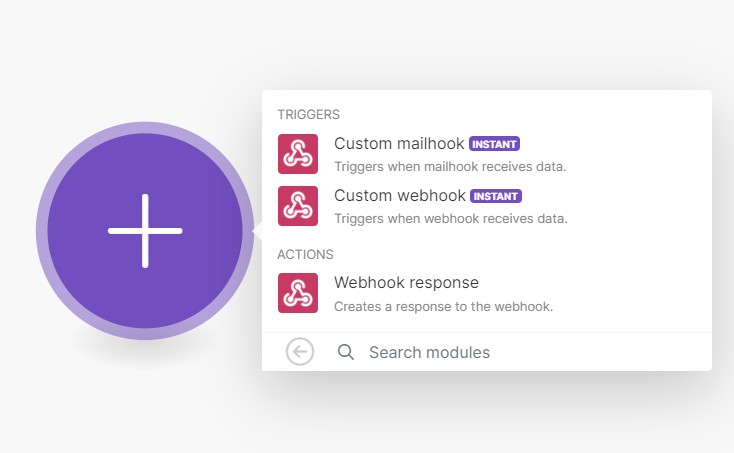
作成されたノードでCreate WebhookをクリックするとWebhookのURLが生成されるのでコピーしておきましょう。

できたら背景をクリックした後Add another moduleをクリックし、受信した情報を処理するためのノードを作成します。
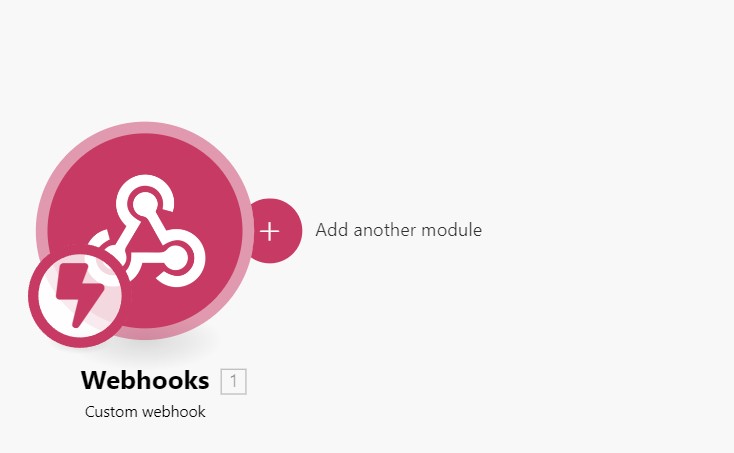
ここでGCPのPub/subsとかに送信すれば、GCPを経由してPythonで処理ができたりします。
Make上では直接コードが書けないので、ソースコードを利用したい場合は
何らかの手段でコードが実行できる環境にデータを飛ばさないといけません。
ノーコードツールにコードは邪道!ということらしい?
で、今回はどうしたかというと、GoogleSheetに飛ばしました。
GoogleSheetsというノードがあるので作成します。
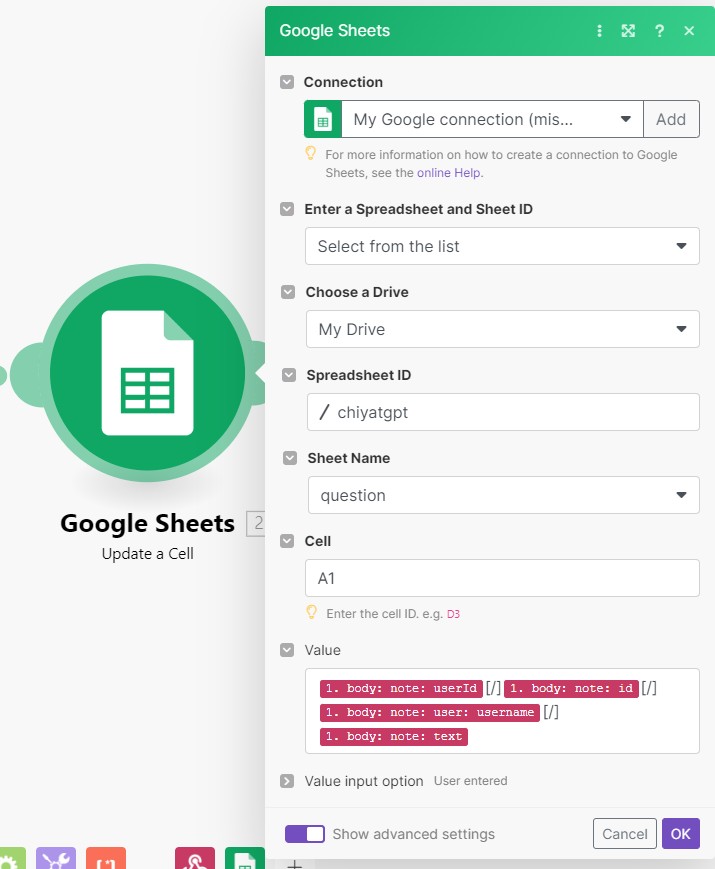
一番上のconnetctionのAddを選択することでGoogleアカウントとの紐づけを行うことができます。
そうしたらGoogleDrive上にデータを受信するためのスプレッドシートを作成し、
そのスプレッドシートIDをシート名、転記先のセルをそれぞれ入力します。
最後のValueにセルに記載するデータを入れます。
jsonデータを一度Webhookに流すことでMake側がjsonの形式を認識してくれるので、
特定のキーの情報のみを取得することも可能です。
今回はリプライを行うのでノートのユーザIDとノートのID、@から始まるユーザーネーム、
そしてテキスト本文を取得します。
これでMake側は終了です。シナリオを保存しましょう。
先ほどのScenariosの画面に戻って、作成したシナリオがOFFになっていればONにします。
次にMisskeyの設定です。ここではWebhookの設定とAPIの作成をします。
Misskieyのbotアカウントを作成、ログインしたら
設定->その他の設定からWebhookを選択して「Webhookを作成」をクリックします。

名前は適当に、シークレットも任意で設定しておきましょう。
URLの部分に先ほどMakeでWebhookを作成した時にコピーしたURLを入力します。
あと「Webhookを実行するタイミング」では「メンションされたとき」のみを選択します。
「返信された時」だと既存のノートに対するリプライしか拾えないので注意です。
次にAPIです。
先ほどのように、設定->その他の設定からAPIを選択して「アクセストークンを発行」をクリックします。
Misskeyのアクセストークンはかなり複雑な権限設定が可能です。
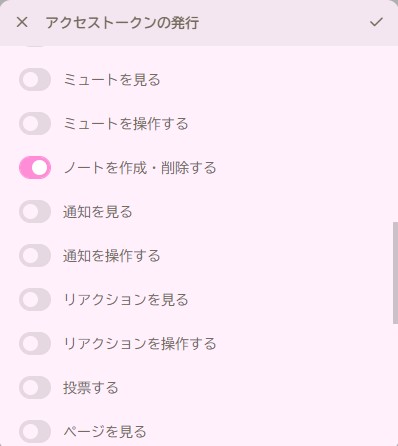
今回は「ノートを作成・削除する」だけで十分でしょう。権限は少なければ少ないほどいいです。
設定が終わったら左上のチェックボタンをクリックで完了です。
最近の流行りらしく、アクセストークンはこの時一度しか表示されないので、確実にコピーしてください。
まぁ紛失したら消して作り直そう
で、最後。GoogleSheet側です。今回はGASを使ってなんとかしていきます。
拡張機能→AppsScriptからスクリプトをクリックしてスクリプトを作っていきます。
今回はこんな感じで応答システムを作ってます。
GASには当然MisskeyAPIは存在しないのでUrlFetchApp.fetchで直接叩いてる感じです。
今回はソースの機能を明確にするために
画像なしノート、画像ありノート、画像なしリプ、画像ありリプ、DMで関数名を分けています。
PythonのMisskeyAPIみたいに、ひとつの関数に集約してもいいと思いますが、今回はソースのわかりやすさ重視です。
処理としてはまず、get_question()で受け取った情報をパースしています。
Make側で要素ごとにノードを作ってバラバラのセルに転記する方法も考えたのですが、後述するトリガの都合上、
Make側のノードの数だけget_question()が走ってしまうのでこのような構成になっています。
次に、パースした情報をsearch_reply()に投げています。
このソースだけではわからない情報なのですが、
別のシートにWebhookで飛んできた質問の単語とそれに対する回答の一覧がありまして、
質問内容に登録した質問の単語があるかを検索し、
それに対応する回答のセルの内容をリプライするような流れになっています。
画像つきノートをする場合にはMisskeyの場合、事前に画像をアップロードした上で
アップロード時の戻り値から、画像IDを拾ってそれをfileIdsとして付与するのですが、
GoogleとMisskeyのセキュリティポリシーの違いから、
GAS上ではMisskieyからの戻りを受けることができないようで、
しょうがなく事前に画像をアップロードしてから、手動で画像IDを確認してシートに貼って参照しています。
で、このソースを稼働させる方法ですが、GASのトリガーを利用します。
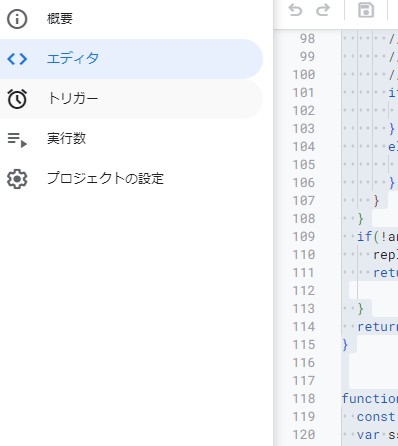
左サイドバーのトリガーを選択、画面右下の「トリガーを追加」から新しいトリガーを作ります。
このように設定してスプレッドシートの変更時にget_question()関数が走るように設定します。
これでbotにリプライが来たらWebhookがmakeのシナリオに飛び、
それを受けてMakeのシナリオによってGoogleSheetに内容が転記され、
スプレッドシートが変更されるのでそれをトリガにGASが走ってbotが返信する
という一連のシステムを作ることができました。
但し、勘の言い方は気づくかと思いますが、スプレッドシート変更がトリガになっているため
同一スプレッドシート内のシートを手動で変更すると、そのたびにget_question()関数が走ってしまいます。
実はそれを回避するように今回のソースは作られているのですが、
冷静に考えると、変なソース作らなくても受け答えの対応表を別のスプレッドシートに置くだけで解決しましたねコレ
まぁとりあえず動いているのでヨシ!ということで(おい
と、まぁ最後駆け足でしたが、だいたいこんな感じです。
そんなに難しい事はしていないつもりなので、Misskeyで対話型botを作りたい方は参考にして頂ければと思います。
因みにMakeはChatGPTが使えるので、APIトークンをお持ちの方はbotに簡単に実装ができるはずなのでおススメです。
ではでは~~~~
(^・ω・)ノ RadiumProduction at curonet
今回はタイトルの通り、対話botを作る話です。
Misskeyのインスタンスを建てた話。①(Misskey紹介編)
Misskeyのインスタンスを建てた話。②(GCPでの建ち上げ編)
Misskeyのインスタンスを建てた話。③(OCIでの建ち上げ編)
普通はMisskeyの立ち上げと来たら設定とか、オブジェクトストレーシとか
そういう記事が次に来るべきだとは思うのですが、
そういうの、もうあるじゃん。
インターネットの海にアホほど転がっている情報を、今更ここで焼き鈍すことに価値があるのか?
と言うことで、ネットの海になさそうな情報を記事として書くことにしました。
Tips
・Misskeyの設定は基本的に管理画面からできます。
・~/misskey/.config/default.yml を編集することでサーバ側の設定ができます。
・特に個人サーバの場合はCloudflareによる保護を検討しましょう。
・オブジェクトストレージはウチはCloudflare R2を使ってます。おススメです。
以上終わり!多分この辺の単語でググればいろいろ出てきます!
まぁ暇だったらウチでちゃんと記事を書くかもしれませんが、余り暇じゃないので多分書かないです。
で、本題なのですが、Twitterではbotと言えば、Streamをでツイートを取得してから自分宛てのツイートを拾って、
それに対して返信をしていく・・・みたいな処理になったかと思うのですが、
何故か今回は違う方法を使っています。
MisskeyにもStream機能はあって実際に使ってみたりもしたのですが、受信はできた
MisskeyのストリーミングAPIはドキュメントが雑にしか書かれていなくて使い方が殆どわからなく、
ネットにも特に新しい情報がないのでよくわからなかったのと、
inputパラメータに何があるかくらいは書いて欲しいんですよね・・・
全てのノートをストリーミングする処理はぼっと用サーバにかかる負担が大きくなることから、
今回は別の手法としてMisskeyに実装されているWebhookを採用しました。
Webhookというのは簡単に言うとネットワークに対して発信できる通知機能のようなものですね。
今回はMisskeyのbotアカウントへのメンションをトリガにして、Webhookを飛ばします。
飛んでくるデータ形式はjsonですので、受け取りさえできれば扱いは簡単です。
それを受けて返信を書いてやろうという魂胆です。
ただ、Webhookは受信用のサーバを建てる必要があります。pythonのモジュールで簡単に建つは建つのですが、
今回はオンプレサーバは使いたくないし、これ以上OCIにもGCPにも負荷をかけたくなかったので
Makeというノーコードツールを導入することにしました。
これはノーコードでアプリケーションパイプラインを構築することができるツールで
月間1000回までなら無料で利用することができます。
まずアカウントを作ってたら左サイドバーのScenariosをクリックしてから右上のCreate a new scenarioを選択します。
そしたらシナリオ画面に行くので真ん中の丸を押して新しいノードを作ります。
今回はWebhookの受信をするので、下の検索欄にwebと打ってWebhooksを選択します。
3つ出てくるのでCustom Webhookを選択します。
作成されたノードでCreate WebhookをクリックするとWebhookのURLが生成されるのでコピーしておきましょう。
できたら背景をクリックした後Add another moduleをクリックし、受信した情報を処理するためのノードを作成します。
ここでGCPのPub/subsとかに送信すれば、GCPを経由してPythonで処理ができたりします。
Make上では直接コードが書けないので、ソースコードを利用したい場合は
何らかの手段でコードが実行できる環境にデータを飛ばさないといけません。
ノーコードツールにコードは邪道!ということらしい?
で、今回はどうしたかというと、GoogleSheetに飛ばしました。
GoogleSheetsというノードがあるので作成します。
一番上のconnetctionのAddを選択することでGoogleアカウントとの紐づけを行うことができます。
そうしたらGoogleDrive上にデータを受信するためのスプレッドシートを作成し、
そのスプレッドシートIDをシート名、転記先のセルをそれぞれ入力します。
最後のValueにセルに記載するデータを入れます。
jsonデータを一度Webhookに流すことでMake側がjsonの形式を認識してくれるので、
特定のキーの情報のみを取得することも可能です。
今回はリプライを行うのでノートのユーザIDとノートのID、@から始まるユーザーネーム、
そしてテキスト本文を取得します。
これでMake側は終了です。シナリオを保存しましょう。
先ほどのScenariosの画面に戻って、作成したシナリオがOFFになっていればONにします。
次にMisskeyの設定です。ここではWebhookの設定とAPIの作成をします。
Misskieyのbotアカウントを作成、ログインしたら
設定->その他の設定からWebhookを選択して「Webhookを作成」をクリックします。
名前は適当に、シークレットも任意で設定しておきましょう。
URLの部分に先ほどMakeでWebhookを作成した時にコピーしたURLを入力します。
あと「Webhookを実行するタイミング」では「メンションされたとき」のみを選択します。
「返信された時」だと既存のノートに対するリプライしか拾えないので注意です。
次にAPIです。
先ほどのように、設定->その他の設定からAPIを選択して「アクセストークンを発行」をクリックします。
Misskeyのアクセストークンはかなり複雑な権限設定が可能です。
今回は「ノートを作成・削除する」だけで十分でしょう。権限は少なければ少ないほどいいです。
設定が終わったら左上のチェックボタンをクリックで完了です。
最近の流行りらしく、アクセストークンはこの時一度しか表示されないので、確実にコピーしてください。
まぁ紛失したら消して作り直そう
で、最後。GoogleSheet側です。今回はGASを使ってなんとかしていきます。
拡張機能→AppsScriptからスクリプトをクリックしてスクリプトを作っていきます。
今回はこんな感じで応答システムを作ってます。
function postToMisskey(text, options) {
return UrlFetchApp.fetch(
`https://${options.server}/api/notes/create`,
{
'method': 'POST',
'headers' : {'Content-Type': 'application/json'},
'payload':JSON.stringify({i : options.token, text: text})
}
);
}
function postToMisskeyWithFile(text, file_ids, options) {
return UrlFetchApp.fetch(
`https://${options.server}/api/notes/create`,
{
'method': 'POST',
'headers' : {'Content-Type': 'application/json'},
'payload':JSON.stringify({i : options.token, text: text, fileIds: file_ids})
}
);
}
function replyToMisskey(text, note_id, options) {
return UrlFetchApp.fetch(
`https://${options.server}/api/notes/create`,
{
'method': 'POST',
'headers' : {'Content-Type': 'application/json'},
'payload':JSON.stringify({i : options.token, text: text, replyId: note_id})
}
);
}
function replyToMisskeyWithFile(text, file_ids, note_id, options) {
return UrlFetchApp.fetch(
`https://${options.server}/api/notes/create`,
{
'method': 'POST',
'headers' : {'Content-Type': 'application/json'},
'payload':JSON.stringify({i : options.token, text: text, fileIds: file_ids, replyId: note_id})
}
);
}
function dmToMisskey(text, usr,options) {
return UrlFetchApp.fetch(
`https://${options.server}/api/notes/create`,
{
'method': 'POST',
'headers' : {'Content-Type': 'application/json'},
'payload':JSON.stringify({i : options.token, text: text,visibility: 'specified',visibleUserIds:[usr]})
}
);
}
function get_question() {
const options={server: 'サーバ名', token: 'アクセストークン'};
var ss = SpreadsheetApp.getActiveSpreadsheet();
var sh = ss.getSheetByName("question");
if(sh.getRange(1,1).isBlank()){
console.log("blank");
return 0;
}
let celldata=sh.getRange(1,1).getValue();
let mention =celldata.split("[/]");
let re_scrname=/(^@.*?) /;
let question = mention[3].replace(re_scrname,"");
sh.getRange(1,1).clear();
}
function search_reply(note_id,question) {
const options={server: 'サーバ名', token: 'アクセストークン'};
var ss = SpreadsheetApp.getActiveSpreadsheet();
var sh = ss.getSheetByName("reply");
key=sh.getRange(1,1,sh.getLastRow(),1).getValues();
text=sh.getRange(1,2,sh.getLastRow(),1).getValues();
file_ids=sh.getRange(1,3,sh.getLastRow(),1).getValues();
let ans=false;
for(let i=0;i<sh.getLastRow();i++){
if(key[i][0]==""){
continue;
}
let re_key=key[i][0].toLowerCase();
let res = question.match(re_key);
if(res){
ans=true;
if(file_ids[i][0]!=""){
replyToMisskeyWithFile(text[i][0], file_ids[i], note_id, options);
}
else{
replyToMisskey(text[i][0], note_id, options);
}
}
}
return 0;
}
上の方は単純に投稿する系の関数ですね。GASには当然MisskeyAPIは存在しないのでUrlFetchApp.fetchで直接叩いてる感じです。
今回はソースの機能を明確にするために
画像なしノート、画像ありノート、画像なしリプ、画像ありリプ、DMで関数名を分けています。
PythonのMisskeyAPIみたいに、ひとつの関数に集約してもいいと思いますが、今回はソースのわかりやすさ重視です。
処理としてはまず、get_question()で受け取った情報をパースしています。
Make側で要素ごとにノードを作ってバラバラのセルに転記する方法も考えたのですが、後述するトリガの都合上、
Make側のノードの数だけget_question()が走ってしまうのでこのような構成になっています。
次に、パースした情報をsearch_reply()に投げています。
このソースだけではわからない情報なのですが、
別のシートにWebhookで飛んできた質問の単語とそれに対する回答の一覧がありまして、
質問内容に登録した質問の単語があるかを検索し、
それに対応する回答のセルの内容をリプライするような流れになっています。
画像つきノートをする場合にはMisskeyの場合、事前に画像をアップロードした上で
アップロード時の戻り値から、画像IDを拾ってそれをfileIdsとして付与するのですが、
GoogleとMisskeyのセキュリティポリシーの違いから、
GAS上ではMisskieyからの戻りを受けることができないようで、
しょうがなく事前に画像をアップロードしてから、手動で画像IDを確認してシートに貼って参照しています。
で、このソースを稼働させる方法ですが、GASのトリガーを利用します。
左サイドバーのトリガーを選択、画面右下の「トリガーを追加」から新しいトリガーを作ります。
このように設定してスプレッドシートの変更時にget_question()関数が走るように設定します。
これでbotにリプライが来たらWebhookがmakeのシナリオに飛び、
それを受けてMakeのシナリオによってGoogleSheetに内容が転記され、
スプレッドシートが変更されるのでそれをトリガにGASが走ってbotが返信する
という一連のシステムを作ることができました。
但し、勘の言い方は気づくかと思いますが、スプレッドシート変更がトリガになっているため
同一スプレッドシート内のシートを手動で変更すると、そのたびにget_question()関数が走ってしまいます。
実はそれを回避するように今回のソースは作られているのですが、
冷静に考えると、変なソース作らなくても受け答えの対応表を別のスプレッドシートに置くだけで解決しましたねコレ
まぁとりあえず動いているのでヨシ!ということで(おい
と、まぁ最後駆け足でしたが、だいたいこんな感じです。
そんなに難しい事はしていないつもりなので、Misskeyで対話型botを作りたい方は参考にして頂ければと思います。
因みにMakeはChatGPTが使えるので、APIトークンをお持ちの方はbotに簡単に実装ができるはずなのでおススメです。
ではでは~~~~
(^・ω・)ノ RadiumProduction at curonet
前回に引き続き、第3回の記事です。
今回はタイトルの通り、OCIでサーバーを建ててみますよ。
Misskeyのインスタンスを建てた話。①(Misskey紹介編)
Misskeyのインスタンスを建てた話。②(GCPでの建ち上げ編)
といっても建て方は同じMisskeyなので、GCPと同じです。
ではなんでこんな記事を?というところなのですが、OCIは。。。その難しいというかなんというか。
多分、無理なんです。情報なしでは。
ということで今回僕が通った道をご紹介させていただきます。
まず、なんでOCI?という話なのですが、
OCIにもGCPと同じコンピューティングインスタンスのAlwaysFree枠がありまして、
圧倒的にOCIの方が優秀なんです。
OCIはAlwaysFreeではAMDとARMのどちらかのインスタンスを利用できます。
ARMインスタンスがその中でもぶっちぎりで性能が高いということで
OCIのARMインスタンスがAlwaysFreeに加わったときは界隈に衝撃が走りました。
※因みに今日本含む極東のリージョンでは、某国がVPNで使いまくるせいでARMインスタンスがほぼ取れません
比較するとこれくらいの差があります。
※OCIのストレージはAMDマシン2台とARMマシン合わせて200GBまで、2ブロックまで無料なので3台利用は不可
※ベンチマークはUnixBenchより
CPUの個数は(個々の仕様が不明なので)性能には特に関係ありませんが、
OCIのARMはGCPと異なり、AlwaysFreeの枠内でリソースの分割が可能でして、
1CPU=1マシンとすればARMの場合は最大4台までAlwaysFreeで利用可能です。
・・・で、見ればわかると思うですが、
衝撃が走っていない方のAMDインスタンスですら、GCPよりつよつよです。それも圧倒的に。
そんなものが2台も使えるのです。無料で。
しかもリージョンがOCIは全地域の中から無料で使いたいリージョンを自由に1カ所選ぶことができるので
日本だと東京、大阪を選ぶことができます。これは8800㎞離れたオレゴンが最短のGCPとは雲泥ですね。
※2度目ですが、今日本含む極東のリージョンでは、某国がVPNで使いまくるせいでARMインスタンスがほぼ取れません
しかも、GCPって何かと理由を付けて謎課金を作ることで有名です。勝手にマルチリージョンでキャッシュ作ったりとかなとかかんとか
なんだかんだGCPでずっとマシンを動かしてると、AlwaysFreeでも課金が大なり小なり発生するものです。
でもOCIにはそれがない。
料金プランが単純明快なので、GCPのように課金レポートとにらめっこしながら
謎課金の原因を探す日々から解放されるのです。
・・・ここまで性能が違えば、
これはOCIに行くっきゃない!!!
ってなるはずなのですが、現実はそうなっていません。OCIのARMがデビューしてからもう2年近くが経ちますが、
未だにコンピューティングの無料インスタンスと言えばGCP一強です。
なんでそんなことになっているのかというと、まぁ広報の問題もあるんでしょうが、単純に
OCIは初見殺しゲーなんです。
※何度も言いますが、今日本含む極東のリージョンでは、某国がVPNで使いまくるせいでARMインスタンスがほぼ取れません
それを今から解説します。
まず、OCIにはFree trialアカウントと有料アカウントの2種類のアカウントがあります。
で、個人の場合、いきなり有料アカウントにはなれなくて、まずトライアルアカウントを作成する必要があります。
そしてそのアカウント登録ページがこちらです。
検索で出てこないのでまずここに辿り着けない人が多いらしい。。。?
で、まず2FAがあるのでメールアドレスを登録してメールを待つのですが、、、
①メールが届かない
これが結構ありがちだそうです。現在、OCIの登録ではSMS認証は廃止になったので一律メールなのですが、
これが届かないケースが結構あるそうです。
OCI公式からは「一度登録に使ったメールアドレスは使えない」という趣旨の発表がありましたが、
未使用でも普通に弾かれるという報告がネット上では相次いでおります。
ただ、どうにもその多くが独自ドメインからのメールのようで、
GmailやYahooメールなどのフリーメールを試されることをお勧めします。
※僕はGmailで一発で行ったのでこの現象に出くわしておりません。
またこれとは別に、これ以降の工程で引っかかると、メール受取からやり直しになるのですが、
「数回メールの受信をすると同一IPからは45分間はメールを受け取れなくなる」のだそうです。
※OracleCloud LiveAgent回答より。多分日本語情報だとらじぷろにしか書いてない情報です。
なので何回か先の工程で引っかかるとメールの送信制限に捕まります。
僕はこれに捕まりました。
そして次にOCIでは本人確認としてアカウント作成時にクレジットカードの与信請求を行うようになっておりまして、
Free trialアカウントでもクレカの登録が必須です。ここはGCPと同じですね
ただ、GCPと違うのはFree trialアカウントのうちは
「何をやっても課金が発生しない」というとことでしょうか。
そういう意味ではGCPより安心して使えます。
ただ、そのクレカ登録で大きな問題がありまして
②クレカの検証で弾かれる
実はこれも僕はスルーしたのですが、多くの人が(体感8割)がここで弾かれて登録を諦めております。
これについては、公式からの発表として
(a) プリペイドカードを登録している。
これが一番業が深いようで、インターネット上で様々な検証がされておりまして、
・住所は関係ない
・デビットカードはダメ
・クレカの発行会社が関係している
など、色々な議論が展開されております。
これらについて、ひとつずつらじぷろの見解を述べさせていただきます。
有識者の立場から言わせてもらえば、まぁ「住所が関係ない」は事実ですね。
クレカの与信請求において住所情報を照合する手段は存在しない(そもそも住所照合は技術自体が困難)ので、
世界中から登録が行われる国際サービスの、それもたかがFree Tialの登録段階において
わざわざ特別な手段を別途作成してまでそんなことをしている可能性はゼロと考えて良いでしょう。
因みに英語じゃないとダメなんて話はありますが、自分は住所は日本語表記で通っています。
OCIは日本法人あるし日本語でええやろの精神です。
「デビットカードがダメ」も多分正しくて、クレカの与信処理的にこれは弾かれてる可能性が高いです。
確認はしておりませんが、プリペイド系も恐らくアウトだと思います。
で、最後にクレカの発行会社が関係しているも、概ね間違いではないと思います。
というのはこの手の与信請求は「カード会社側で弾かれている可能性が存在する」からです。
特に日本の会社はそれをやる傾向が強いです。あくまで「傾向」の話ですが。
これに関してはOCIではどうすることもできないので、カード会社に電話で確認するのが一番です。
あとは最悪「カードを変えるか」ですね。私はエポスで一発で行きました。
②の結論としては、
「狭義クレカをちゃんと使ってダメなら与信が通っているか会社に確認入れるかカードを変える」
これでいいと思います。まぁ要するにネットの不確定な情報も案外的を得ているな、という感想です。
で、最大の難所がそこまでクリアした上で一番最後に「無料トライアルの開始」を押した時に発生する
③トランザクションエラー
です。
※与信請求時のトランザクションエラーとは別のモノです
これに関しては、解決策がわかりません。
原因も一切不明。完全にお手上げです。
じゃあどうしたかというと、
OracleCloudのCloud Support Chatから
Live Agentを呼び出してもらって解決してもらいました。※全部英語
いや、マジでこれ以外に書きようがないんです。
与信請求も通ってるのにトランサクションエラーとか言うのが出て先に進めないんです、
って英語で問い合わせたら
「ちょっと待ってね」って言われて5分ぐらいしてから
「対応したのでもっぺん同じ情報入れて最初からやってくれ」って言われてやったらできたんです。
つまり、与信を通した後でも、あちら側の理由で何故か申請が弾かれるような何かがあって
「それは問い合わせたら解決する」というのが最終的な僕の答えでした。
そもそも、初見で恐らくこのサポートチャットを見つけてから人間を召喚するのは
難易度ルナティックにも程があります。どういう経緯で見つけたのかは未だに思い出せません。
ここまでの手順が書かれている日本語情報源は、恐らく世界でここだけだと思います。
いや、手順か?これ・・・?
②の与信請求については結構描いてあるサイトが多いのですが、①と③についてはほぼ書かれてませんでした。
今回はタイトルの通り、OCIでサーバーを建ててみますよ。
Misskeyのインスタンスを建てた話。①(Misskey紹介編)
Misskeyのインスタンスを建てた話。②(GCPでの建ち上げ編)
といっても建て方は同じMisskeyなので、GCPと同じです。
ではなんでこんな記事を?というところなのですが、OCIは。。。その難しいというかなんというか。
多分、無理なんです。情報なしでは。
ということで今回僕が通った道をご紹介させていただきます。
まず、なんでOCI?という話なのですが、
OCIにもGCPと同じコンピューティングインスタンスのAlwaysFree枠がありまして、
圧倒的にOCIの方が優秀なんです。
OCIはAlwaysFreeではAMDとARMのどちらかのインスタンスを利用できます。
ARMインスタンスがその中でもぶっちぎりで性能が高いということで
OCIのARMインスタンスがAlwaysFreeに加わったときは界隈に衝撃が走りました。
※因みに今日本含む極東のリージョンでは、某国がVPNで使いまくるせいでARMインスタンスがほぼ取れません
比較するとこれくらいの差があります。
| OCI(AMD) | OCI(ARM) | GCP(Intel Xeon) | |
| CPU | 1個(性能1/8制限) | 4個 | 2個(性能25%制限) |
| メモリ | 1GB | 24GB | 1GB |
| ストレージ | 200GB | 200GB | 30GB |
| ベンチマーク(シングルコア) | 410 | 1871 | 131 |
| ベンチマーク(マルチコア) | 533 | 3801 | 190 |
| リージョン | 全地域 | 全地域 | 北米のみ |
| 利用可能数 | 2台 | 1~4台 | 1台 |
※ベンチマークはUnixBenchより
CPUの個数は(個々の仕様が不明なので)性能には特に関係ありませんが、
OCIのARMはGCPと異なり、AlwaysFreeの枠内でリソースの分割が可能でして、
1CPU=1マシンとすればARMの場合は最大4台までAlwaysFreeで利用可能です。
・・・で、見ればわかると思うですが、
衝撃が走っていない方のAMDインスタンスですら、GCPよりつよつよです。それも圧倒的に。
そんなものが2台も使えるのです。無料で。
しかもリージョンがOCIは全地域の中から無料で使いたいリージョンを自由に1カ所選ぶことができるので
日本だと東京、大阪を選ぶことができます。これは8800㎞離れたオレゴンが最短のGCPとは雲泥ですね。
※2度目ですが、今日本含む極東のリージョンでは、某国がVPNで使いまくるせいでARMインスタンスがほぼ取れません
しかも、GCPって何かと理由を付けて謎課金を作ることで有名です。勝手にマルチリージョンでキャッシュ作ったりとかなとかかんとか
なんだかんだGCPでずっとマシンを動かしてると、AlwaysFreeでも課金が大なり小なり発生するものです。
でもOCIにはそれがない。
料金プランが単純明快なので、GCPのように課金レポートとにらめっこしながら
謎課金の原因を探す日々から解放されるのです。
・・・ここまで性能が違えば、
これはOCIに行くっきゃない!!!
ってなるはずなのですが、現実はそうなっていません。OCIのARMがデビューしてからもう2年近くが経ちますが、
未だにコンピューティングの無料インスタンスと言えばGCP一強です。
なんでそんなことになっているのかというと、まぁ広報の問題もあるんでしょうが、単純に
OCIは初見殺しゲーなんです。
※何度も言いますが、今日本含む極東のリージョンでは、某国がVPNで使いまくるせいでARMインスタンスがほぼ取れません
それを今から解説します。
まず、OCIにはFree trialアカウントと有料アカウントの2種類のアカウントがあります。
で、個人の場合、いきなり有料アカウントにはなれなくて、まずトライアルアカウントを作成する必要があります。
そしてそのアカウント登録ページがこちらです。
検索で出てこないのでまずここに辿り着けない人が多いらしい。。。?
で、まず2FAがあるのでメールアドレスを登録してメールを待つのですが、、、
①メールが届かない
これが結構ありがちだそうです。現在、OCIの登録ではSMS認証は廃止になったので一律メールなのですが、
これが届かないケースが結構あるそうです。
OCI公式からは「一度登録に使ったメールアドレスは使えない」という趣旨の発表がありましたが、
未使用でも普通に弾かれるという報告がネット上では相次いでおります。
ただ、どうにもその多くが独自ドメインからのメールのようで、
GmailやYahooメールなどのフリーメールを試されることをお勧めします。
※僕はGmailで一発で行ったのでこの現象に出くわしておりません。
またこれとは別に、これ以降の工程で引っかかると、メール受取からやり直しになるのですが、
「数回メールの受信をすると同一IPからは45分間はメールを受け取れなくなる」のだそうです。
※OracleCloud LiveAgent回答より。多分日本語情報だとらじぷろにしか書いてない情報です。
なので何回か先の工程で引っかかるとメールの送信制限に捕まります。
僕はこれに捕まりました。
そして次にOCIでは本人確認としてアカウント作成時にクレジットカードの与信請求を行うようになっておりまして、
Free trialアカウントでもクレカの登録が必須です。ここはGCPと同じですね
ただ、GCPと違うのはFree trialアカウントのうちは
「何をやっても課金が発生しない」というとことでしょうか。
そういう意味ではGCPより安心して使えます。
ただ、そのクレカ登録で大きな問題がありまして
②クレカの検証で弾かれる
実はこれも僕はスルーしたのですが、多くの人が(体感8割)がここで弾かれて登録を諦めております。
これについては、公式からの発表として
(a) プリペイドカードを登録している。
(b) 意図的に、または意図せずにユーザーの所在地またはアイデンティティを隠蔽した。
(c) 不完全または不正確なアカウント詳細を入力した。
このどれかに引っかかると弾かれる、とあるのですが、
どれにも引っかからずとも弾かれた例が数多く報告されております。
このどれかに引っかかると弾かれる、とあるのですが、
どれにも引っかからずとも弾かれた例が数多く報告されております。
これが一番業が深いようで、インターネット上で様々な検証がされておりまして、
・住所は関係ない
・デビットカードはダメ
・クレカの発行会社が関係している
など、色々な議論が展開されております。
これらについて、ひとつずつらじぷろの見解を述べさせていただきます。
有識者の立場から言わせてもらえば、まぁ「住所が関係ない」は事実ですね。
クレカの与信請求において住所情報を照合する手段は存在しない(そもそも住所照合は技術自体が困難)ので、
世界中から登録が行われる国際サービスの、それもたかがFree Tialの登録段階において
わざわざ特別な手段を別途作成してまでそんなことをしている可能性はゼロと考えて良いでしょう。
因みに英語じゃないとダメなんて話はありますが、自分は住所は日本語表記で通っています。
OCIは日本法人あるし日本語でええやろの精神です。
「デビットカードがダメ」も多分正しくて、クレカの与信処理的にこれは弾かれてる可能性が高いです。
確認はしておりませんが、プリペイド系も恐らくアウトだと思います。
で、最後にクレカの発行会社が関係しているも、概ね間違いではないと思います。
というのはこの手の与信請求は「カード会社側で弾かれている可能性が存在する」からです。
特に日本の会社はそれをやる傾向が強いです。あくまで「傾向」の話ですが。
これに関してはOCIではどうすることもできないので、カード会社に電話で確認するのが一番です。
あとは最悪「カードを変えるか」ですね。私はエポスで一発で行きました。
②の結論としては、
「狭義クレカをちゃんと使ってダメなら与信が通っているか会社に確認入れるかカードを変える」
これでいいと思います。まぁ要するにネットの不確定な情報も案外的を得ているな、という感想です。
で、最大の難所がそこまでクリアした上で一番最後に「無料トライアルの開始」を押した時に発生する
③トランザクションエラー
です。
※与信請求時のトランザクションエラーとは別のモノです
これに関しては、解決策がわかりません。
原因も一切不明。完全にお手上げです。
じゃあどうしたかというと、
OracleCloudのCloud Support Chatから
Live Agentを呼び出してもらって解決してもらいました。※全部英語
いや、マジでこれ以外に書きようがないんです。
与信請求も通ってるのにトランサクションエラーとか言うのが出て先に進めないんです、
って英語で問い合わせたら
「ちょっと待ってね」って言われて5分ぐらいしてから
「対応したのでもっぺん同じ情報入れて最初からやってくれ」って言われてやったらできたんです。
つまり、与信を通した後でも、あちら側の理由で何故か申請が弾かれるような何かがあって
「それは問い合わせたら解決する」というのが最終的な僕の答えでした。
そもそも、初見で恐らくこのサポートチャットを見つけてから人間を召喚するのは
難易度ルナティックにも程があります。どういう経緯で見つけたのかは未だに思い出せません。
ここまでの手順が書かれている日本語情報源は、恐らく世界でここだけだと思います。
いや、手順か?これ・・・?
②の与信請求については結構描いてあるサイトが多いのですが、①と③についてはほぼ書かれてませんでした。
あと、因みになのですが、OCIはログインも謎です。
ログイン画面で最初に出てくるところに入れるのが、「Cloud Account Name」。
登録時に入れたアカウント名前です。
次に遷移した画面で出てくるところに入れるのは「ユーザー名」とありますが、
入力するのは登録時のメールアドレスです。
この他にもOCIにはテナントネームと言う名前もあり、各所で要求される情報が異なります。
また、テクニカルサポートを受けるには別途Oracleのサポートアカウントを作成してOCIアカウントを紐づけて・・・
みたいなことをする必要があり、正直訳が分かりません。
この辺も全部先ほどのLiveAgentに英語で問い合わせて確認しました。
エージェントとのチャットはメールと違ってリアルタイムで飛んでくるので、
スピーディな返信をしないと勝手にチャットを打ち切られてしまうことから
Google先生に頼らずに英語である程度の技術文章をサクサク書いてサクサク読めないと
多分OCIは無理です。
正直罠だらけなので、誰もお勧めしないのでしょう。書いておいてなんですが、僕もあまりお勧めはしておりません。
※しつこいようですが、今日本含む極東のリージョン、では某国がVPNで使いまくるせいでARMインスタンスがほぼ取れません
。。。というか「勧めた以上発生する責任」に対処することができないから、と言うべきでしょうか。
あと、GCPみたいにコンソールを複数タブ開いて操作するとほぼ100%UIが壊れます。
GCPだと常に支払いを別タブで監視ながら操作するのが一般的ですが、
OCIは複数タブで同じことやると簡単に逝くので課金監視はアプリで別途やりましょう。
・・・とまぁこの通り、全体的にユーザビリティが地平線の彼方に飛んで行ってしまっているわけです。
但し、一度使えるようになってしまえば安いし強いので、心身(特に理不尽に挫けない心)に余裕がある際には
試してみるのもいいのではないでしょうか。
ちなみに私は奇跡的に、
2023年7月に、
東京リージョンで
ARMインスタンスの取得に
成功しました!!!
現在弊Misskeyインスタンスは、この奇跡のARMインスタンス上に乗っています。
それは今日はこの辺で。盛大に長い前フリを決めた上でのただの自慢話でした。
(^・ω・)ノ RadiumProduction at curonet
入力するのは登録時のメールアドレスです。
この他にもOCIにはテナントネームと言う名前もあり、各所で要求される情報が異なります。
また、テクニカルサポートを受けるには別途Oracleのサポートアカウントを作成してOCIアカウントを紐づけて・・・
みたいなことをする必要があり、正直訳が分かりません。
この辺も全部先ほどのLiveAgentに英語で問い合わせて確認しました。
エージェントとのチャットはメールと違ってリアルタイムで飛んでくるので、
スピーディな返信をしないと勝手にチャットを打ち切られてしまうことから
Google先生に頼らずに英語である程度の技術文章をサクサク書いてサクサク読めないと
多分OCIは無理です。
正直罠だらけなので、誰もお勧めしないのでしょう。書いておいてなんですが、僕もあまりお勧めはしておりません。
※しつこいようですが、今日本含む極東のリージョン、では某国がVPNで使いまくるせいでARMインスタンスがほぼ取れません
。。。というか「勧めた以上発生する責任」に対処することができないから、と言うべきでしょうか。
あと、GCPみたいにコンソールを複数タブ開いて操作するとほぼ100%UIが壊れます。
GCPだと常に支払いを別タブで監視ながら操作するのが一般的ですが、
OCIは複数タブで同じことやると簡単に逝くので課金監視はアプリで別途やりましょう。
・・・とまぁこの通り、全体的にユーザビリティが地平線の彼方に飛んで行ってしまっているわけです。
但し、一度使えるようになってしまえば安いし強いので、心身(特に理不尽に挫けない心)に余裕がある際には
試してみるのもいいのではないでしょうか。
ちなみに私は奇跡的に、
2023年7月に、
東京リージョンで
ARMインスタンスの取得に
成功しました!!!
現在弊Misskeyインスタンスは、この奇跡のARMインスタンス上に乗っています。
それは今日はこの辺で。盛大に長い前フリを決めた上でのただの自慢話でした。
(^・ω・)ノ RadiumProduction at curonet
カレンダー
最新CM
カテゴリー
かうんた
らじぷろ目次
らじぷろ検索機
最新記事
(01/01)
(01/12)
(08/29)
(01/03)
(08/27)
(04/29)
(01/01)
(11/20)
(09/06)
(09/04)
(08/09)
(08/06)
(07/27)
(05/29)
(03/15)
プロフィール
HN:
Luz
性別:
男性
アーカイブ